Bayesian Structural Causal Inference
Exploring Space, Finding Structure, Testing Robustness
Preliminaries
Who am I?
- I’m a data scientist at Personio
- Bayesian statistician,
- Reformed philosopher and logician.
- Website: https://nathanielf.github.io/
Code or it didn’t Happen
The worked examples used here can be found here

My Website
The Metaphor
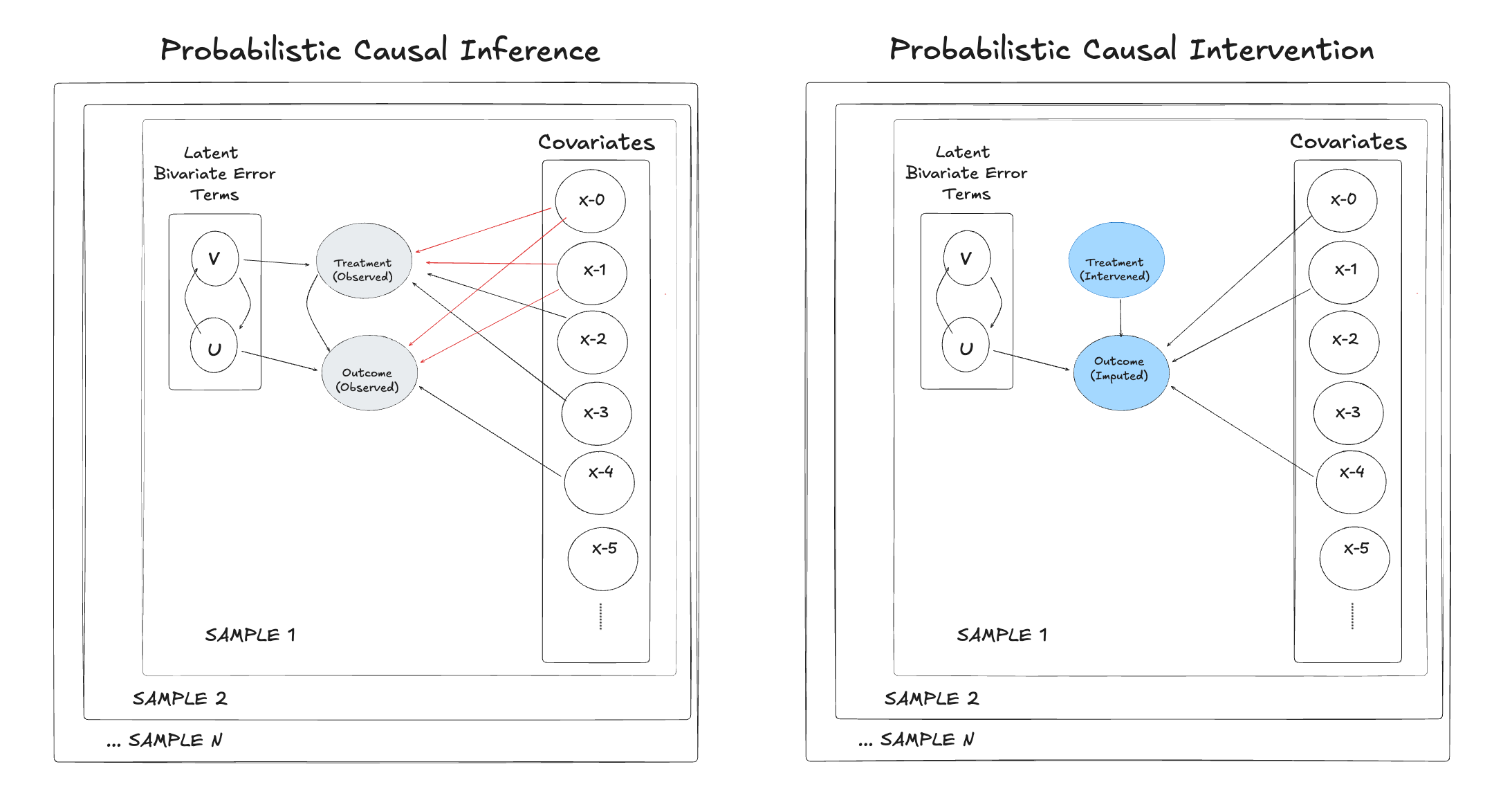
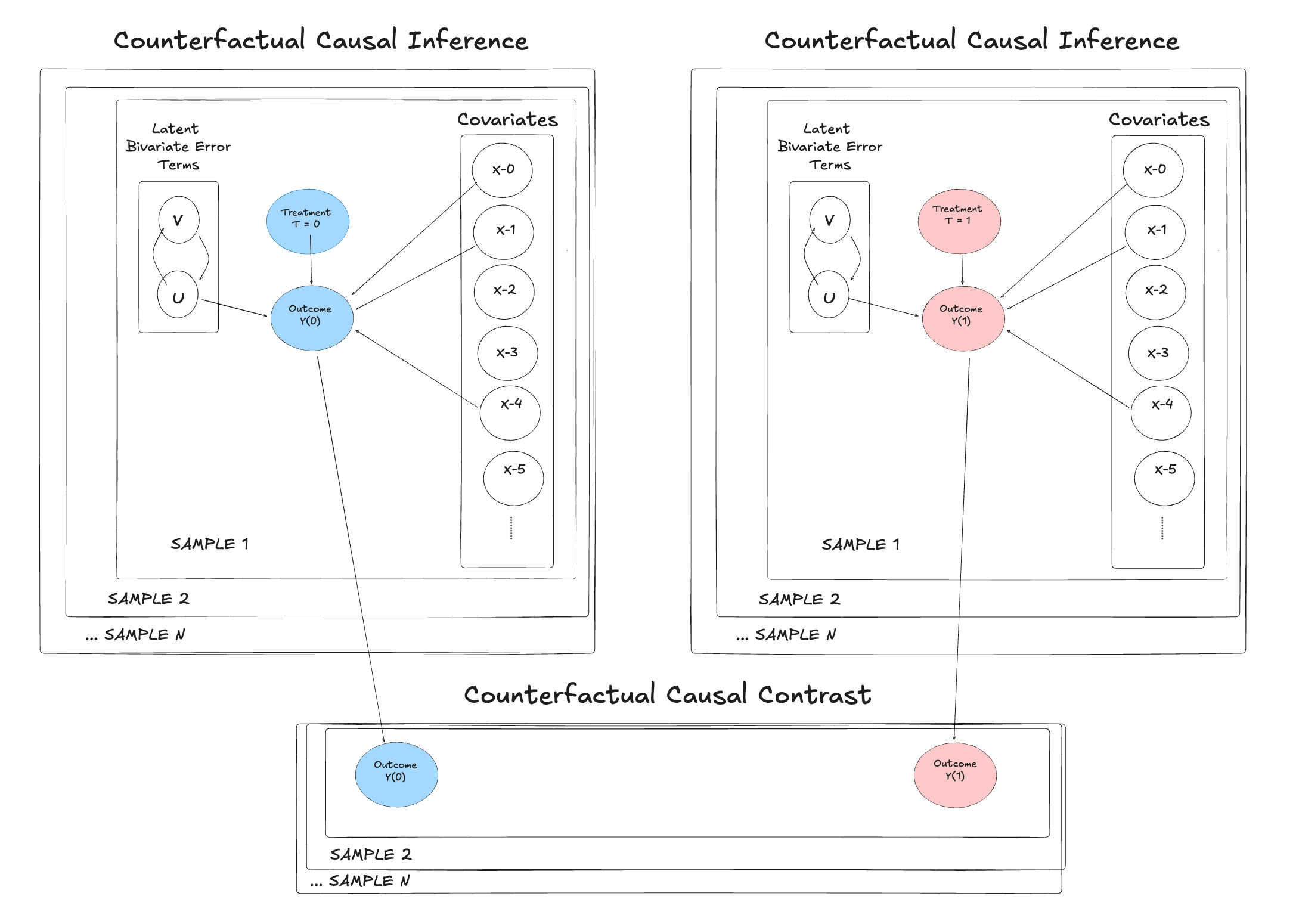
Joint Structural Modelling

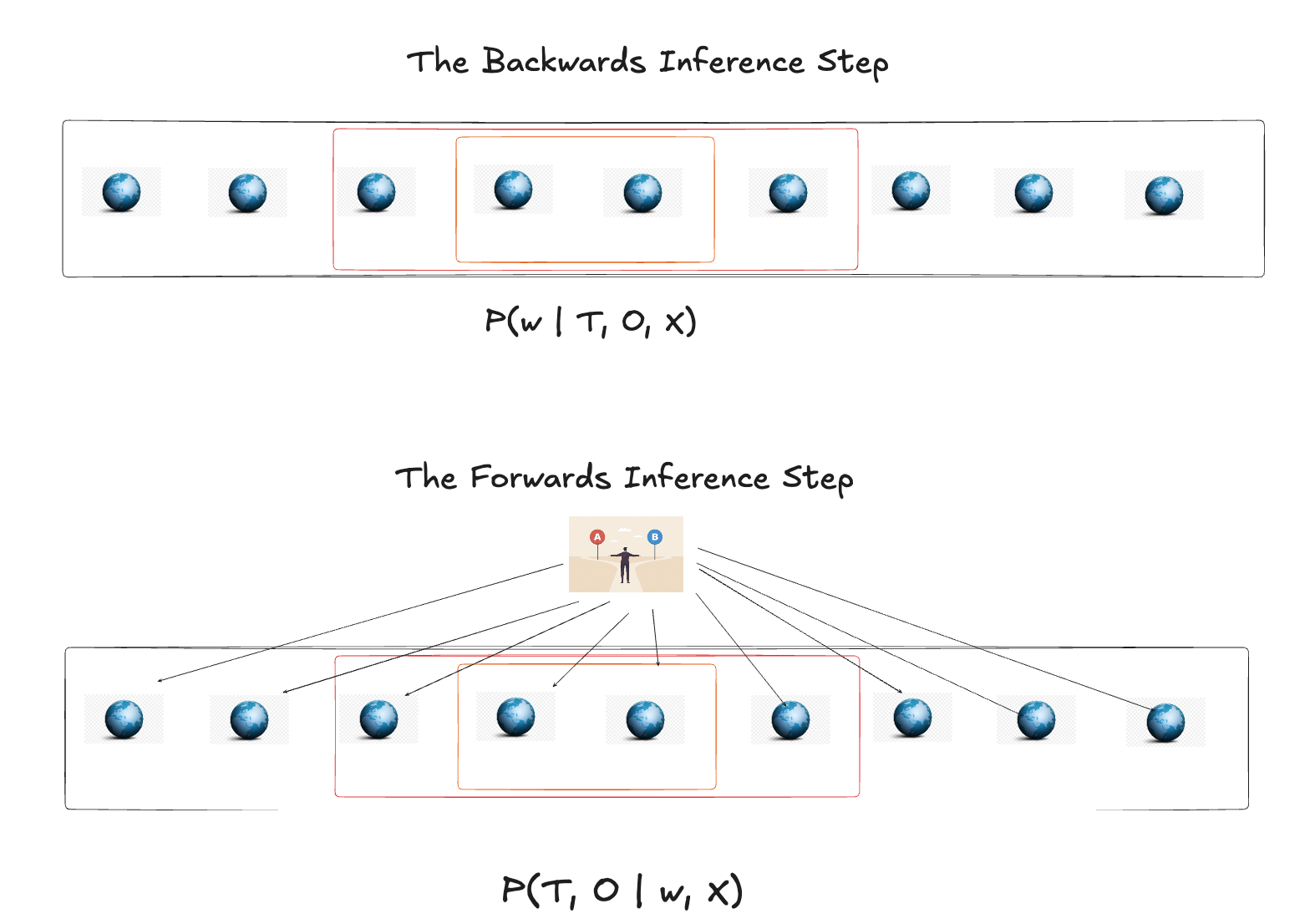
The Two Movements of Inference
Causal inference in a structural framework is a two-step dance:
- Backwards (Inference): Use observed Treatment (\(T\)) and Outcome (\(Y\)) to infer the hidden state of the world (\(w\)).
- Forwards (Counterfactual): Use that world state to simulate what would happen if we changed \(T\).
The Bias is Real: OLS Drift
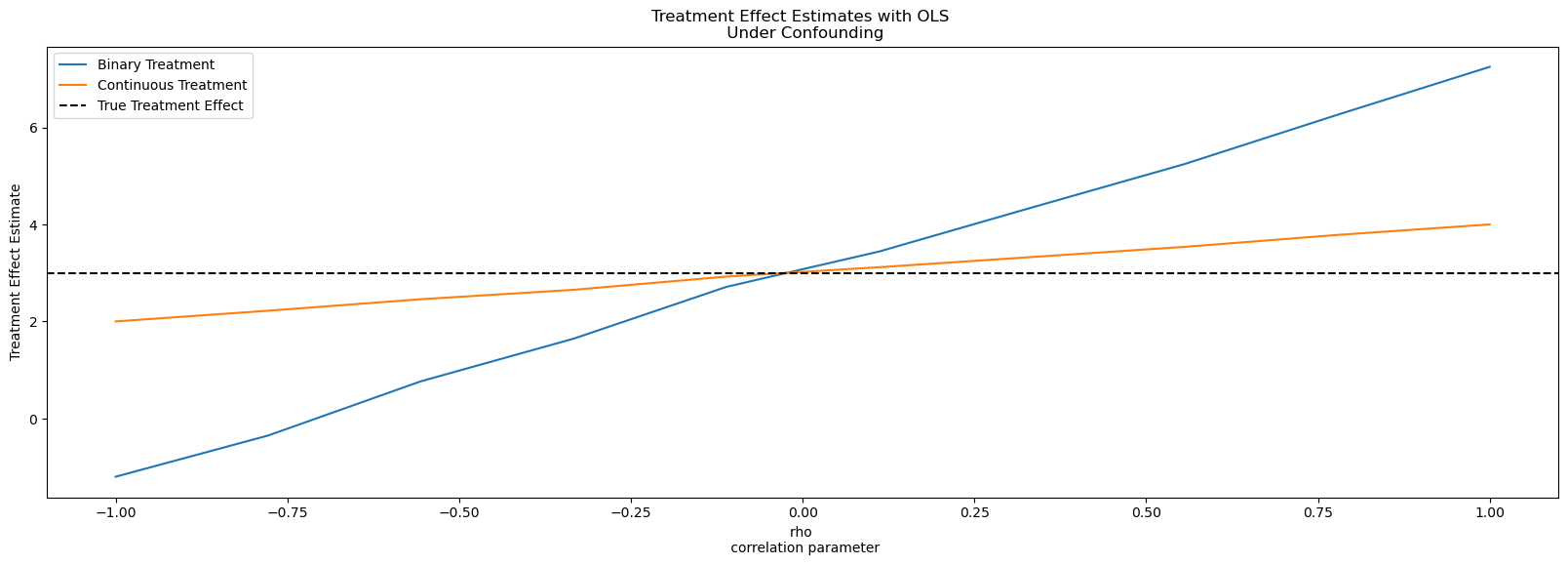
OLS estimates drift as ρ varies
If we ignore \(\rho\), our estimate of the effect (\(\alpha\)) is a ghost. It’s not just “noisy”—it’s fundamentally misplaced because we’ve ignored the unobserved “currents” in the tank.
Variable Selection Priors and Instrument Discovery
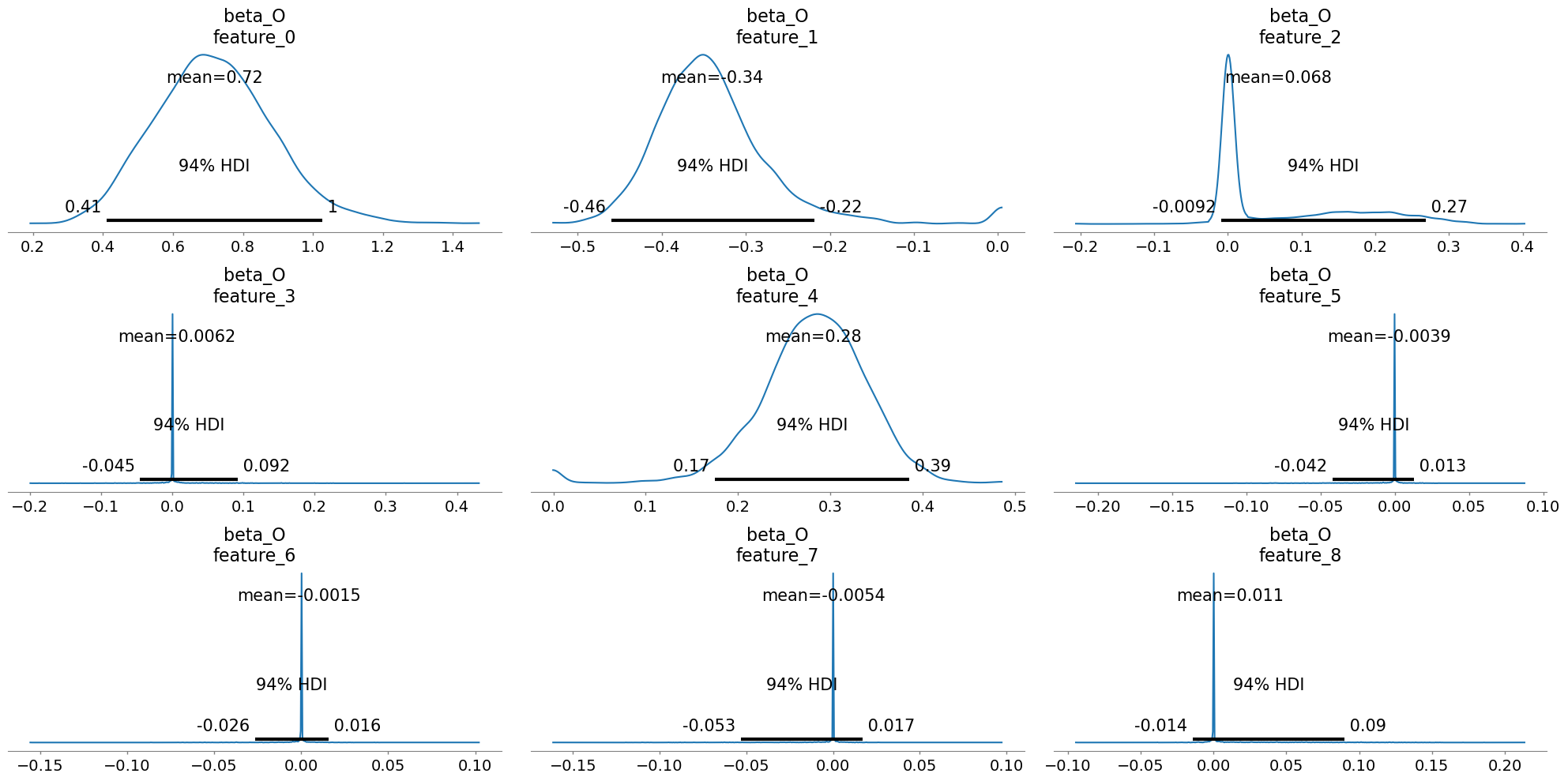
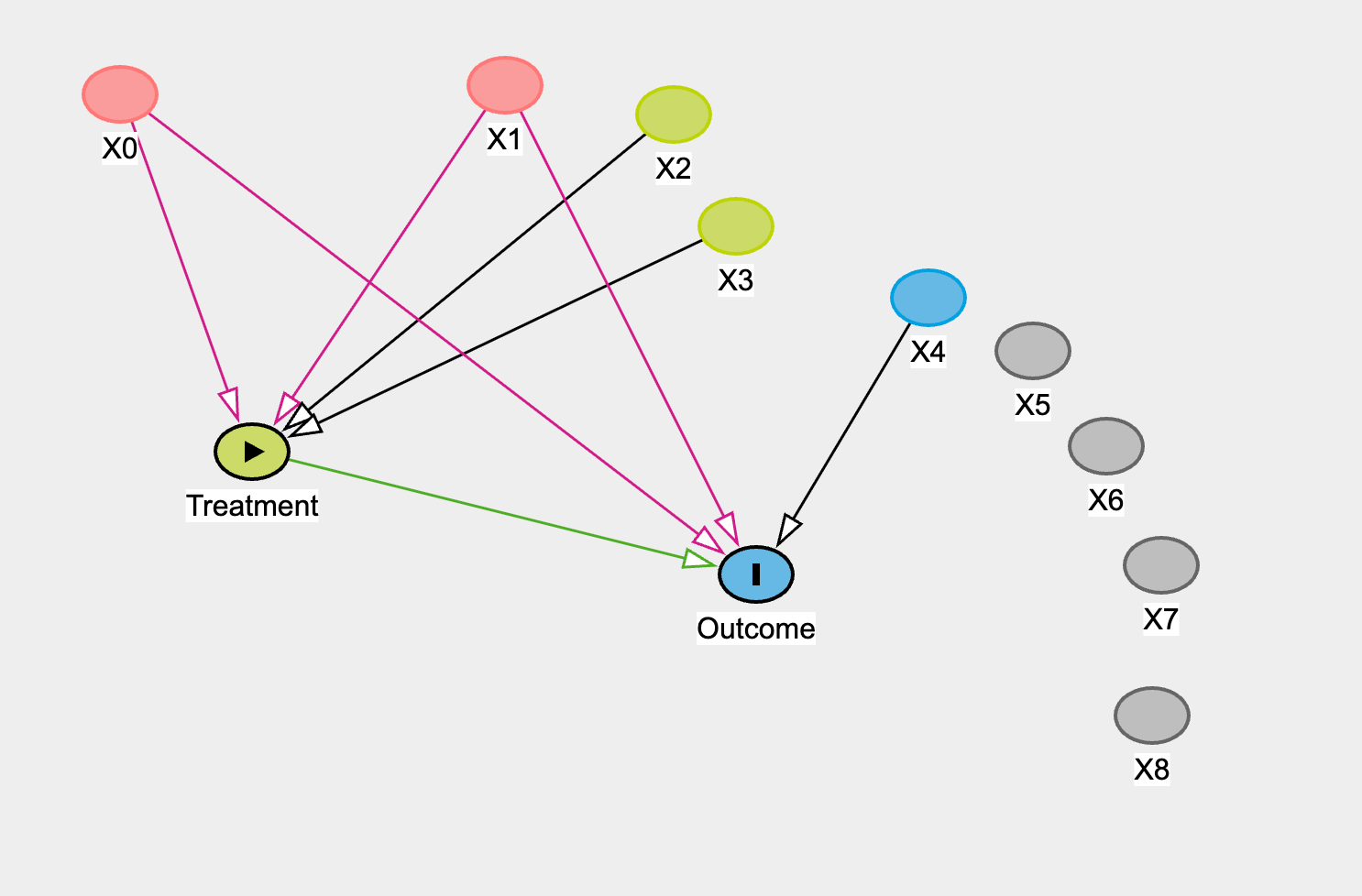
Identification Denied
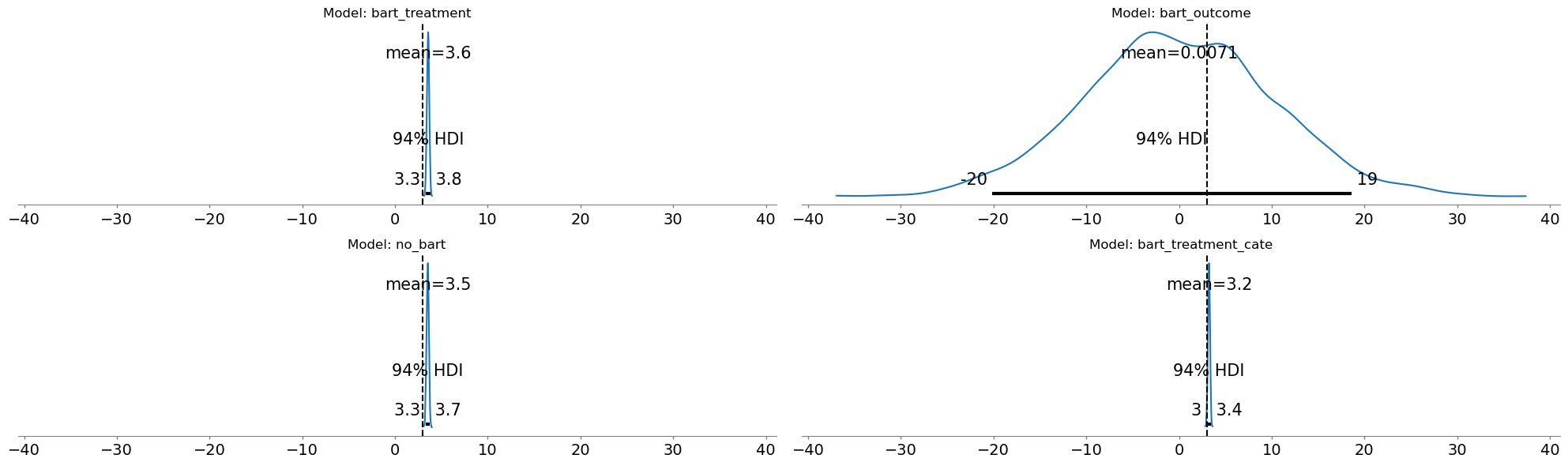
BART outcome model absorbs the structural distinction between treatment and other covariates, rendering the treatment effect surplus to purpose. The signal is swallowed by the noise-handler.
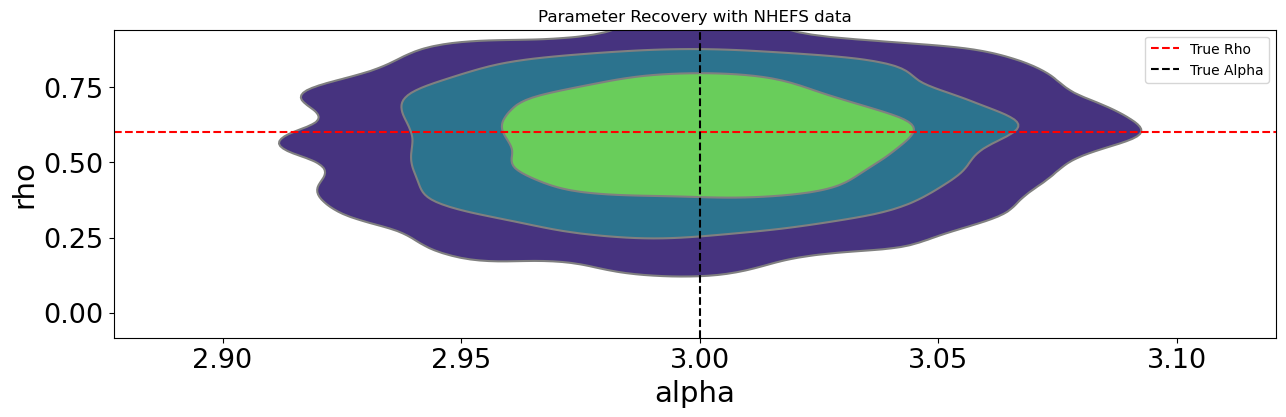
Parameter Recovery

fixed_parameters = {
"rho": 0.6,
"alpha": 3,
"beta_O": [0, 1, 0.4, 0.3, 0.1, 0.8, 0, 0, 0, 0, 0, 0, 3, 0],
"beta_T": [1, 1.3, 0.5, 0.3, 0.7, 1.6, 0, 0.4, 0, 0, 0, 0, 0, 0],
}
with pm.do(nhefs_binary_model, fixed_parameters) as synthetic_model:
idata = pm.sample_prior_predictive(
random_seed=1000
) # Sample from prior predictive distribution.
synthetic_y = idata["prior"]["likelihood_outcome"].sel(draw=0, chain=0)
synthetic_t = idata["prior"]["likelihood_treatment"].sel(draw=0, chain=0)
# Infer parameters conditioned on observed data
with pm.observe(
nhefs_binary_model,
{"likelihood_outcome": synthetic_y, "likelihood_treatment": synthetic_t},
) as inference_model:
idata_sim = pm.sample_prior_predictive()
idata_sim.extend(pm.sample(random_seed=100, chains=4, tune=2000, draws=500))Identification Achieved
Core Principle
Flexibility (capturing complex patterns) and Identification (isolating causal effects) are in tension. Structure the role flexible models well in causal inference.
Mapping the Multiverse
We don’t estimate a point; we map a territory.
Causal Inference and Counterfactual Worlds
Testing Robustness
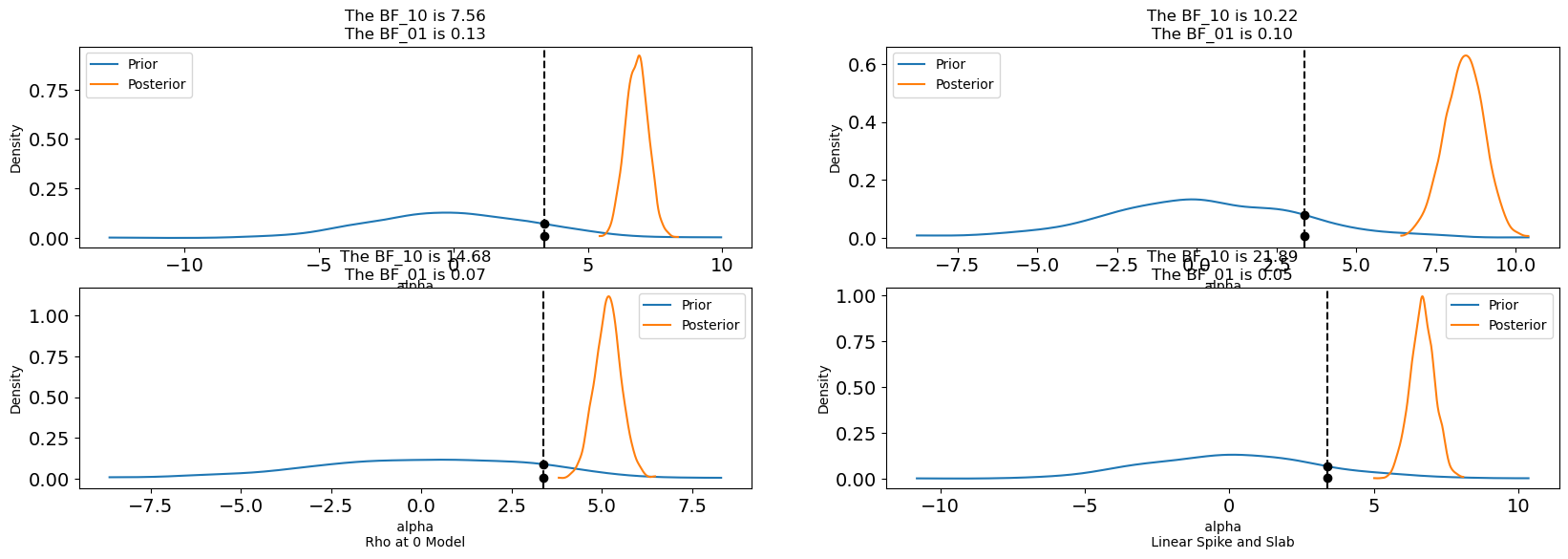
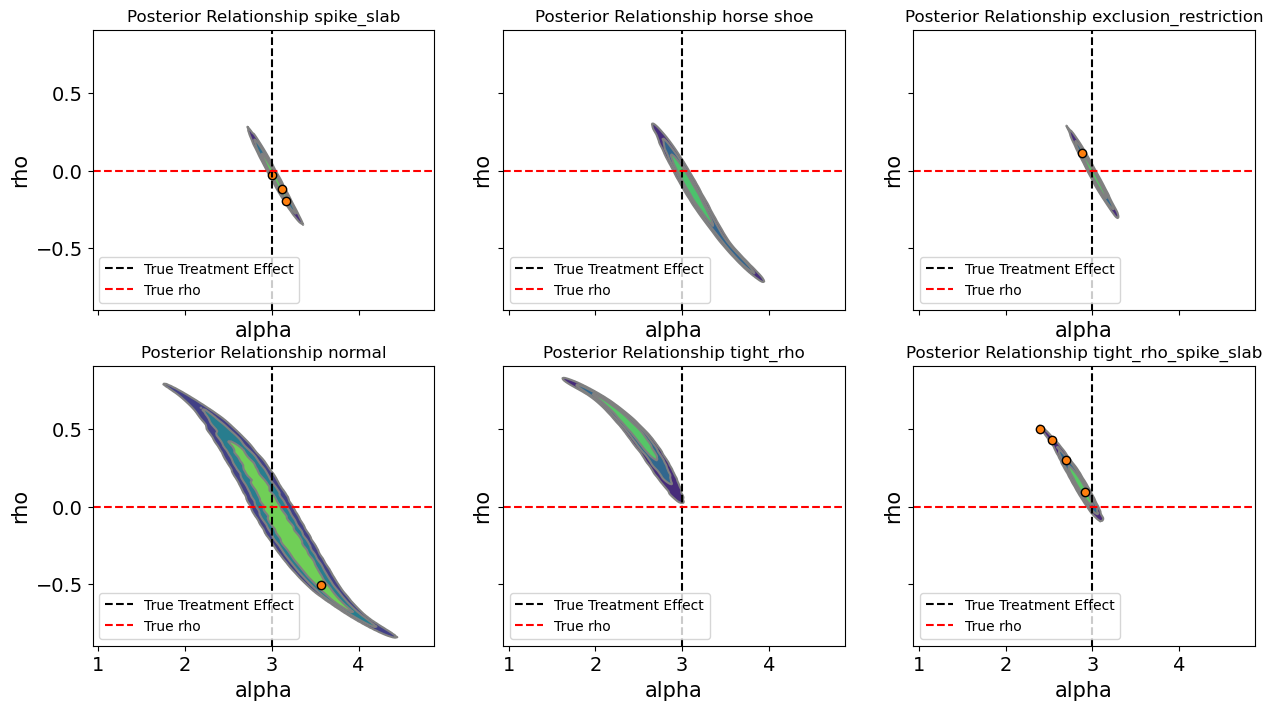
We assess the range of treatment effects under a variety of model specifications including a BART treatment equation. Results suggest some unmeasured confounding distorts the OLS estimate.
The Hard Truth
We can’t prove \(\alpha > 3.3\) But we can: (1) Show it’s plausible given domain knowledge (2) Map the range of effects across ρ values (3) Make robust decisions that work across scenarios