Uncertainty and Causal Inference in Python
CausalPy and Quasi-Experimental Designs
11/16/24
Preliminaries
Who am I?
- I’m a data scientist at Personio
- Bayesian statistician,
- Reformed philosopher and logician.
- Website: https://nathanielf.github.io/
Code or it didn’t Happen
The worked examples used here can be found here

My Website
Data Science in Industry
and other varieties of Satisficing
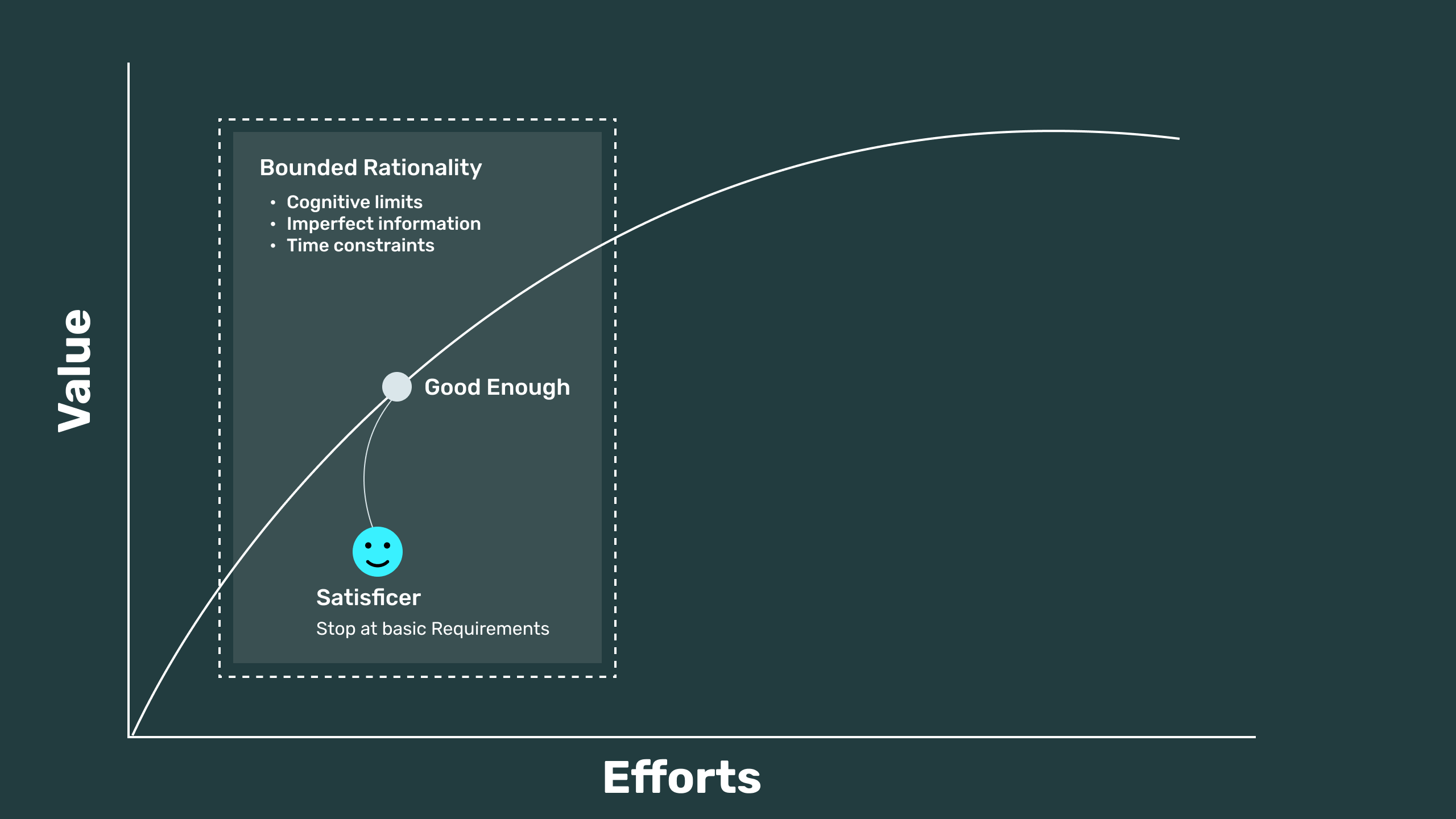
Where do we get to if everyone does the minimum? What is the compounding effect of poor decisions?
Directionally Correct …
Maybe in a ZIRP world
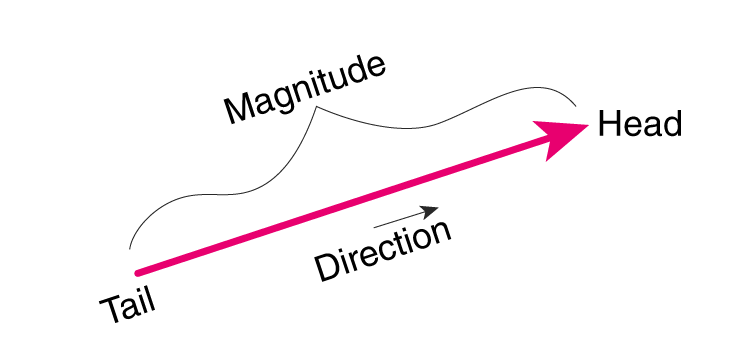
- Important investment decisions require a view of magnitude and direction.
- Most business decisions reflect some kind of investment
- But time and effort are harder to place on a balance sheet
- Only sound causal inference supports generalisable decision rules
- “Directionally Correct” is a Zero-interest-rate-phenomena.
Experiment Recipes, Rules and Responsibility
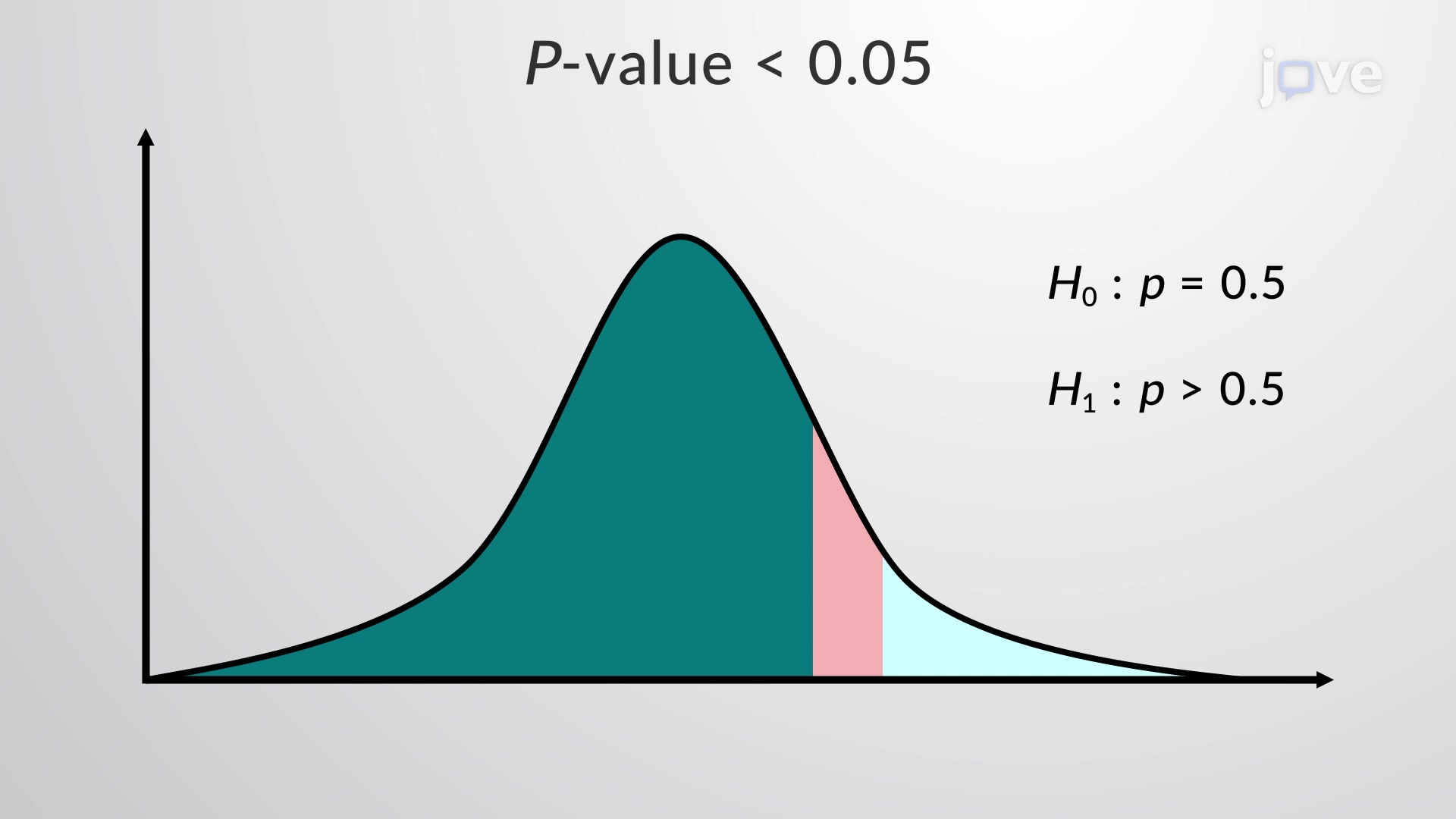

- P-value based decision criteria on policy change questions are based on the null model of an asymptotic univariate distribution.
- Most aggregate data (e.g. Total Revenue) we see in industry result from a complex array of mixture distributions and any long-run aggregates take time to converge.
- Management often doesn’t want to spend the time to validate the long-run characteristics of a phenomena that we would observe in a well powered A/B test.
- Risks underpowered experiments through a HIPPO-like decision rules and costly mistakes, ungeneralisable effects.
- Challenge: How to improve decision quality in a resource constrained/time-bound environment?
Causal Inference, Crediblility
… and Quasi-Experimental Design

- If the data can speak for itself, the answer is usually blindingly obvious or has taken an inordinate amount of time to accumulate
- More generally, if we’ve modeled the data generating process we can answer an array of subtle questions about cause and effect that support effective decision-making.
- Approach: Communicate and pursue opportunities for natural experiments. Build credibility through linking theoretical estimand and empirical data while partnering across the business with subject matter experts.
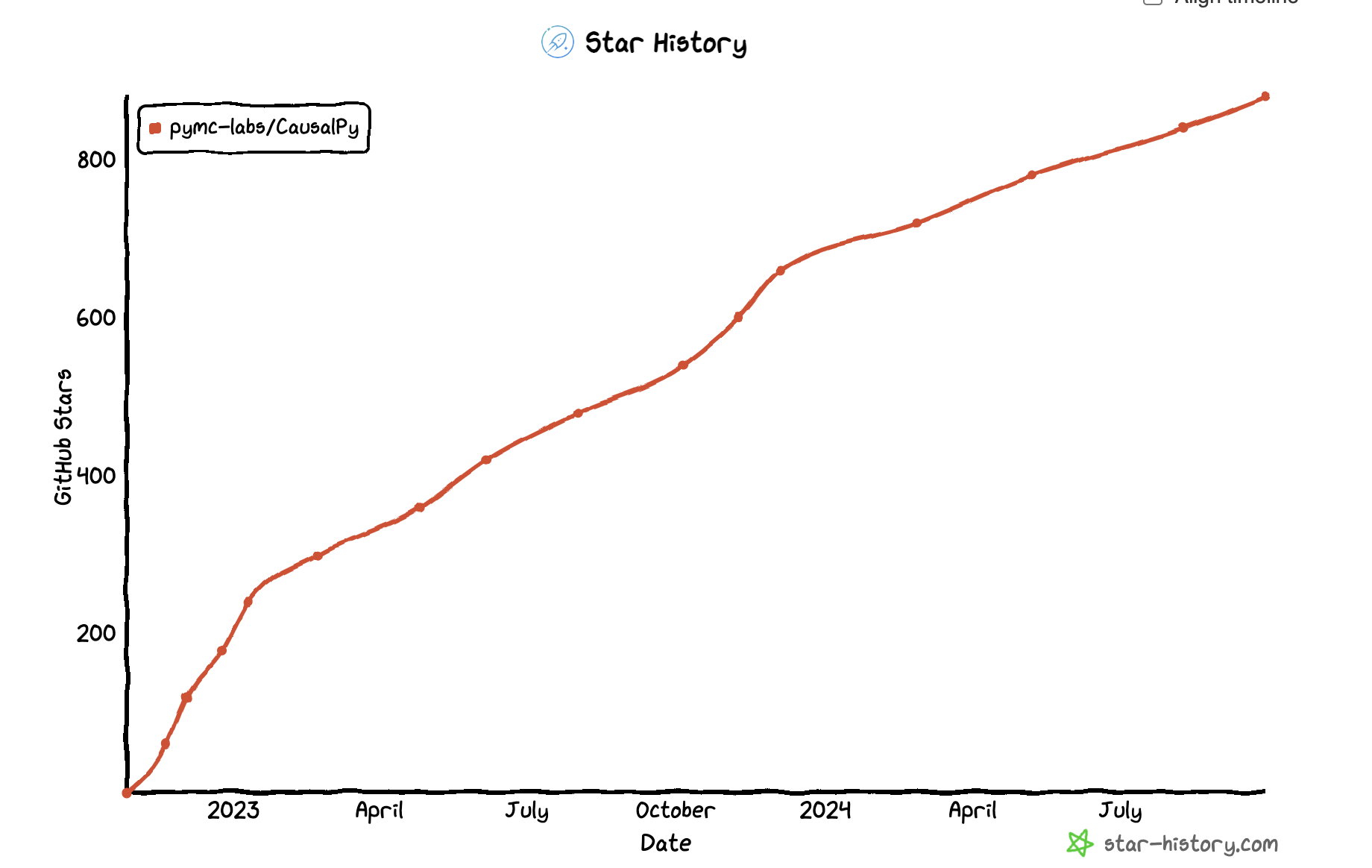
CausalPy and Bayesian Inference

- A python package for Bayesian Models and Causal Inference methods
- Developed and maintained by @PyMC Labs
- Broad Coverage of quasi-experimental designs.
Causal Methods and Models

 Causal question(s) of import can be interrogated just when we can pair a research design with an appropriate statistical model.
Causal question(s) of import can be interrogated just when we can pair a research design with an appropriate statistical model.
Canonical DAGs and Methods
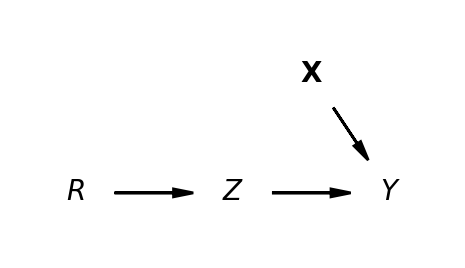
The treatment effect can be estimated cleanly \[ y \sim 1 + Z \]
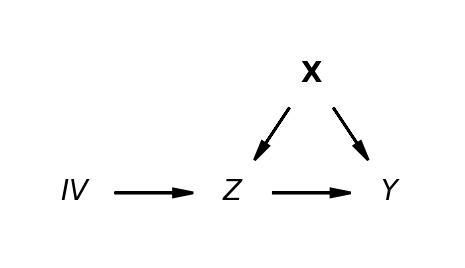
The treatment effect has to be estimated so as to avoid the bias due to X \[ y \sim 1 + \widehat{Z} \] \[ \hat{Z} \sim 1 + IV \]
Returns to Schooling: Concrete Example
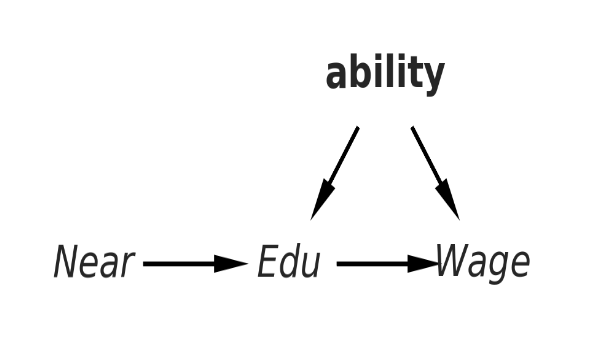
Recipe of Assumptions:
- Exclusion Restriction
- Independence
- Relevance
Returns to Schooling: Instrument Relevance
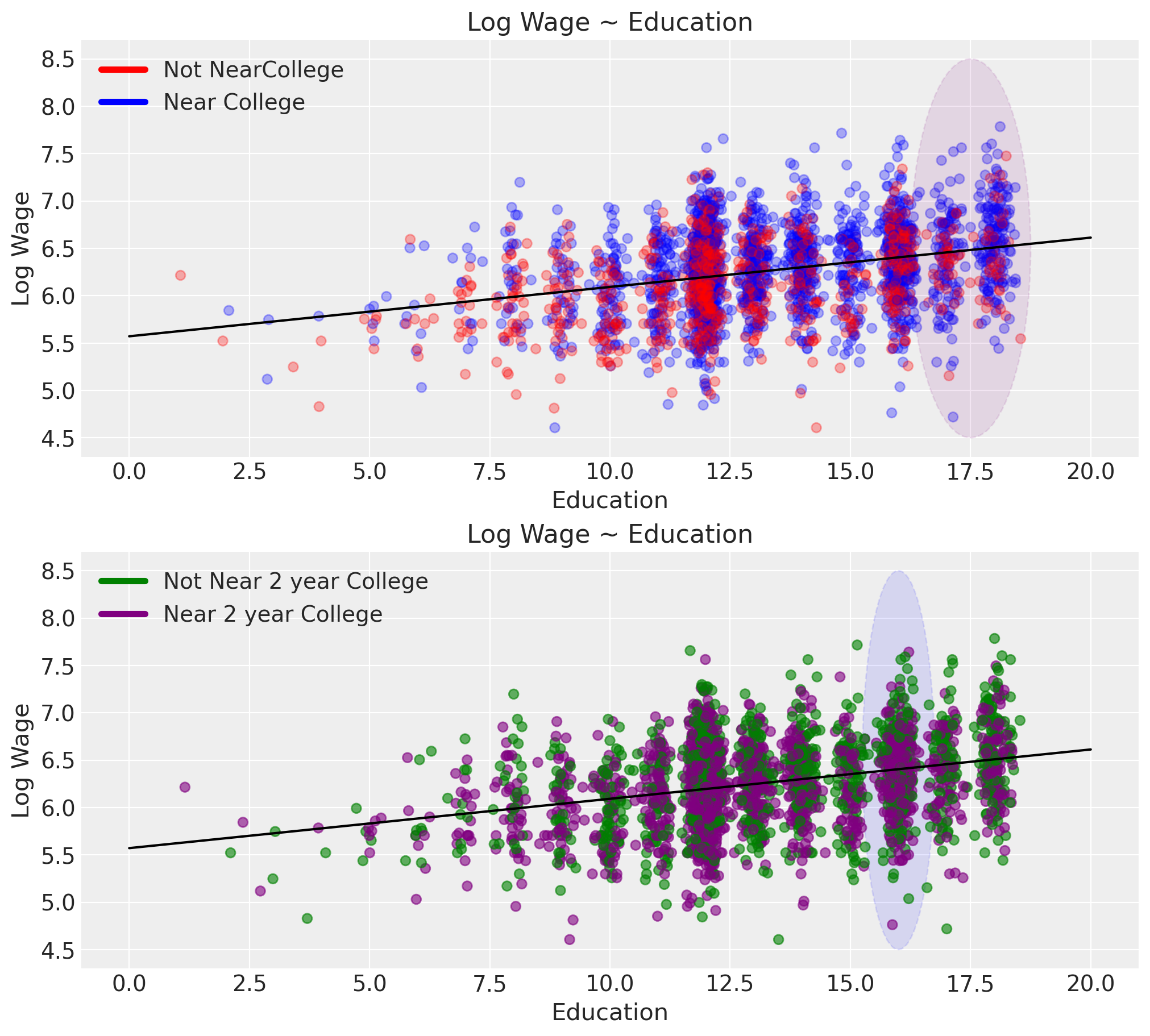
We want to argue for:
the relevance of our instrument i.e. that it has a non-trivial impact on the outcome of interest
that it influences the result only via the treatment condition.
evaluating multiple instrument candidates
Returns to Schooling: Quantifying Confounding
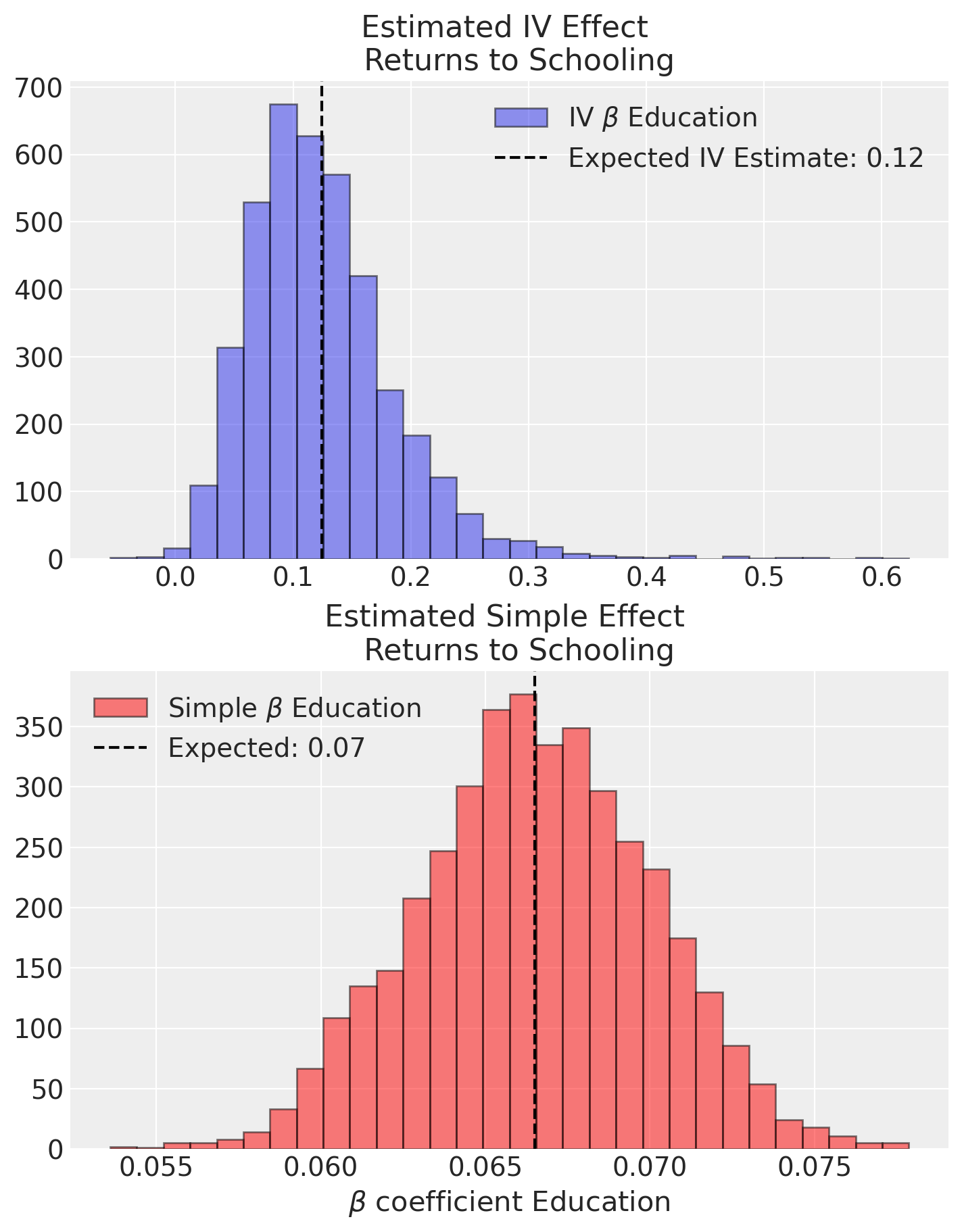
The natural comparison with OLS shows:
evidence of genuine confounding in the estimates of treatment effect
Crucially it highlights the false precision in the OLS estimate.
Model comparison is at the heart of understanding confounding in causal infernece.
IV models may be compared by structure but also by instruments used.
Returns to Schooling: Justifying Instruments
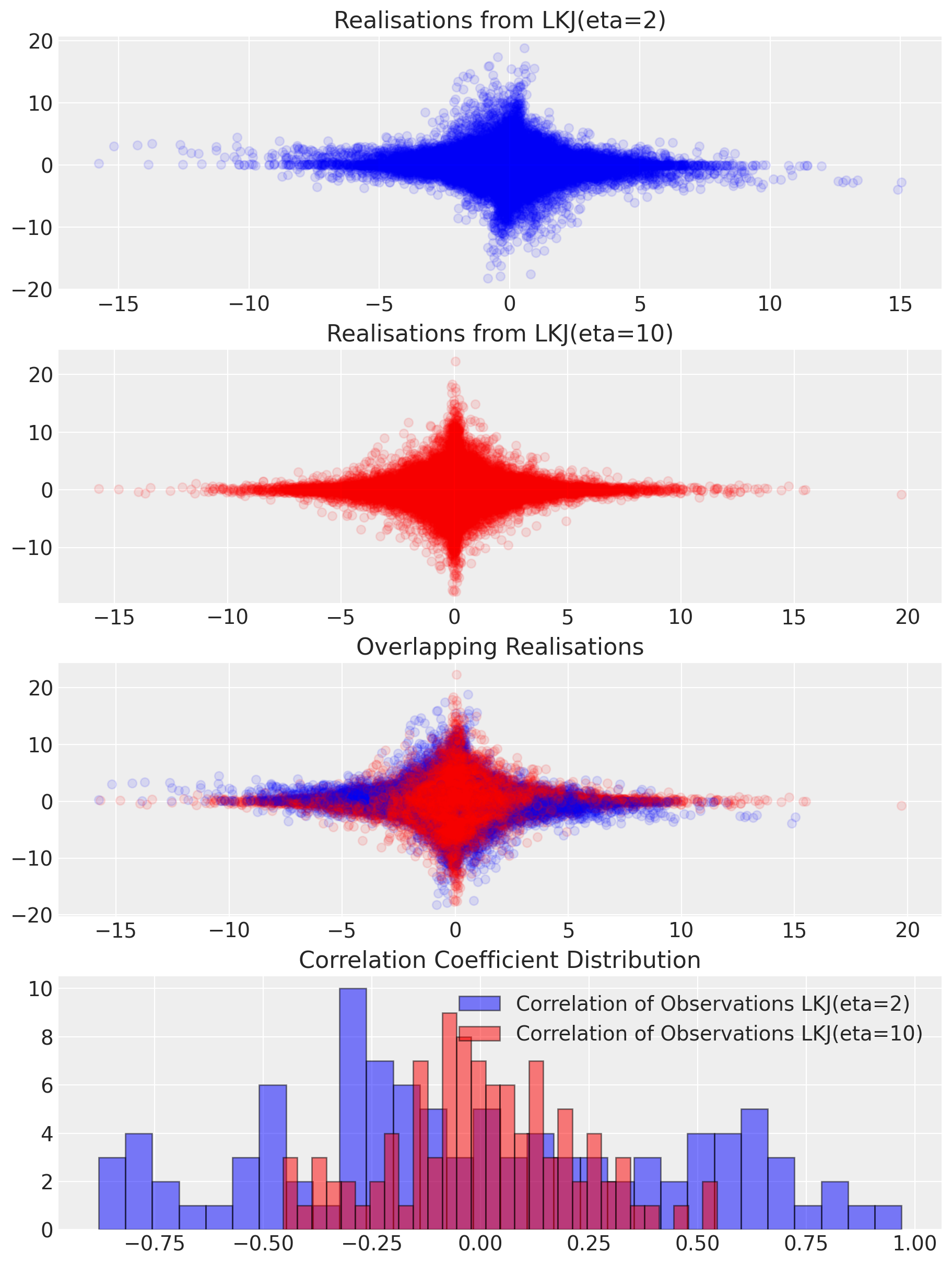
The strength of an instrument is determined by the correlation structure between instrument and outcome via the treatment solely:
F-tests can be used to assess how the instrument relates to the outcome.
In the Bayesian setting we can directly estimate the correlation structure and apply sensitivity tests.
Stronger priors on correlation strength influence the outcomes and can be evaluated against the data through posterior predictive checks
Returns to Schooling: Sensitivity Analysis and Model Evaluation
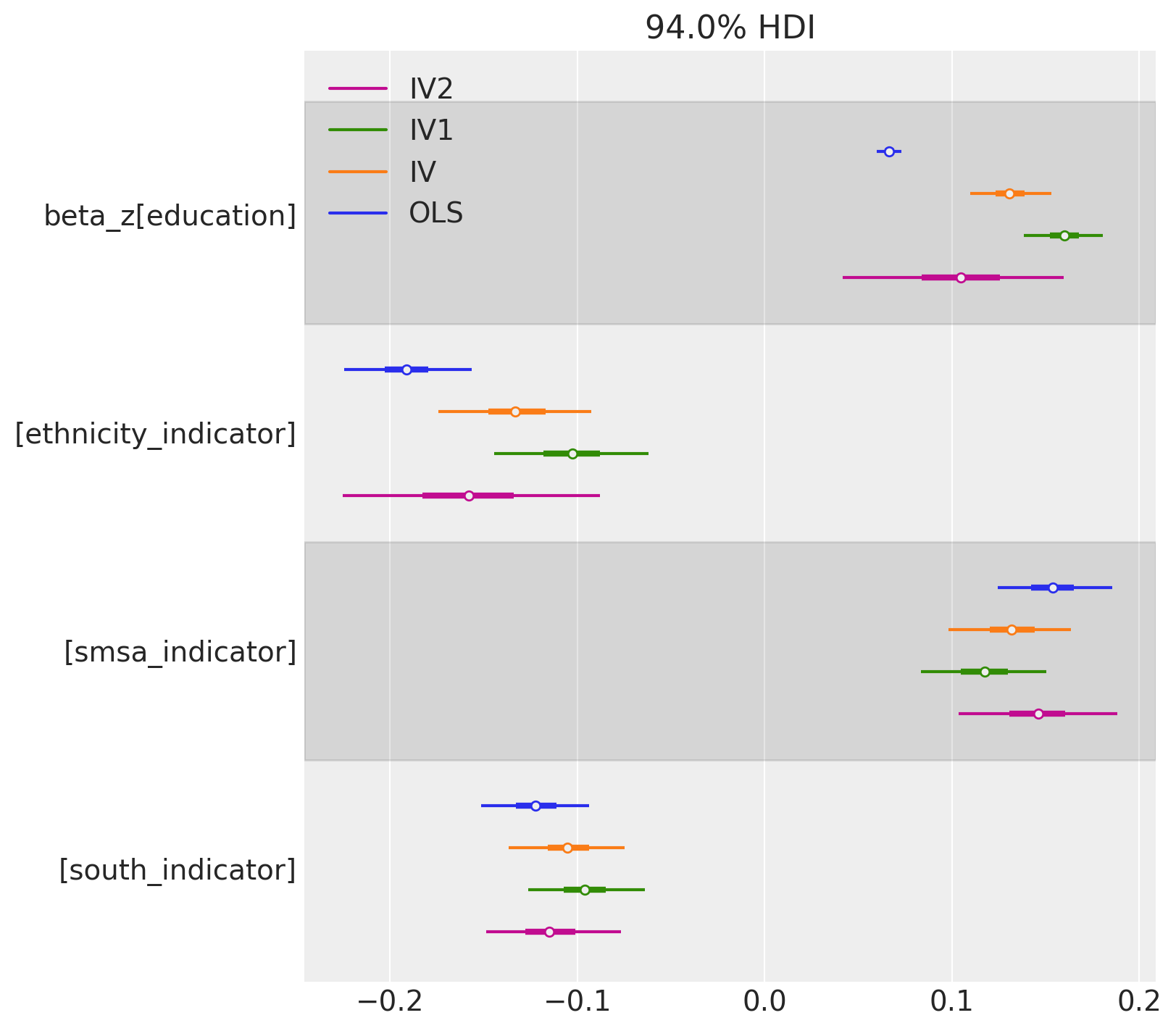
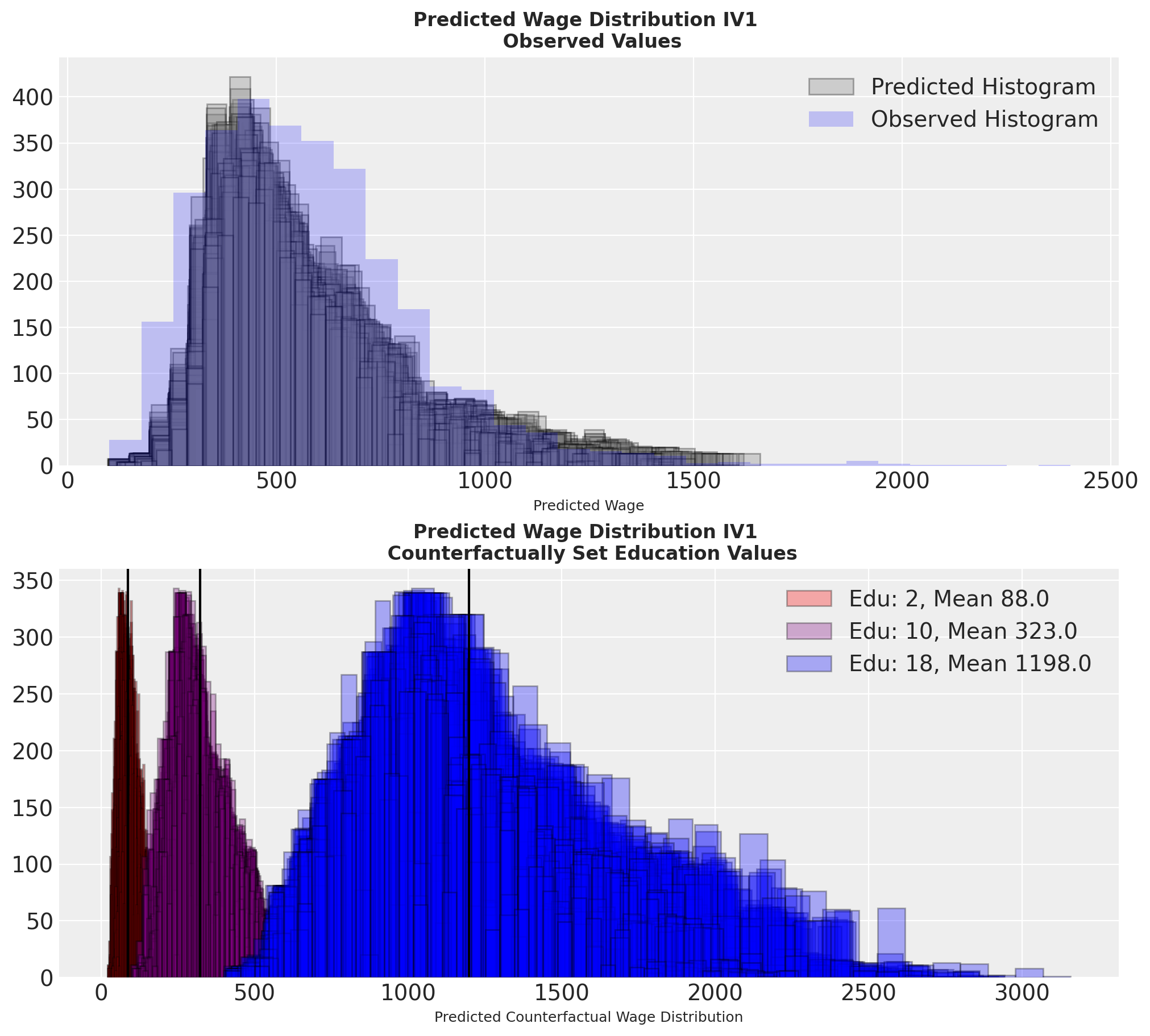
Canonical DAGs and Methods
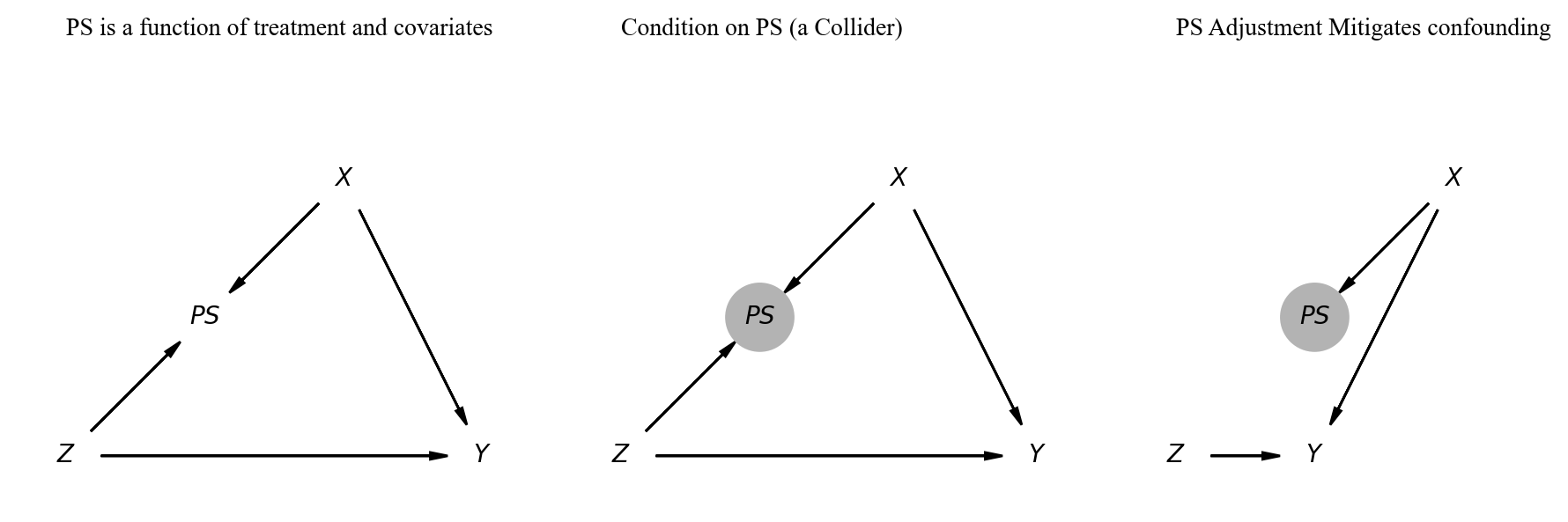
The treatment effect can be estimated cleanly \[ y \sim 1 + Z + X_1 ... X_N \] \[ p(Z) \sim X_1 ... X_N \]
Propensity score adjustments reweight our outcome by the probability of treatment \[ y \sim f(p(Z), Z)\]
Propensity Score Models

Overfitting Propensity Score models to the sample data confounds causal inference
Validating Balancing Effects
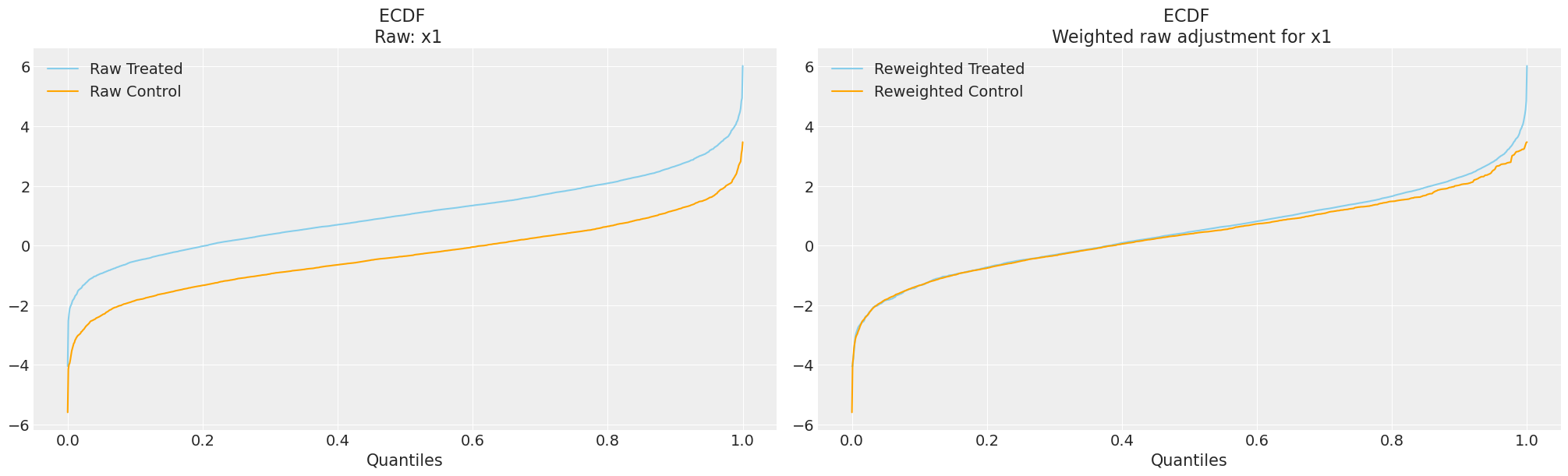
Balancing Covariate Distributions across Treatment Groups
Balanced covariate distributions is testable implication the propensity score design.
Models and Weighting Methods
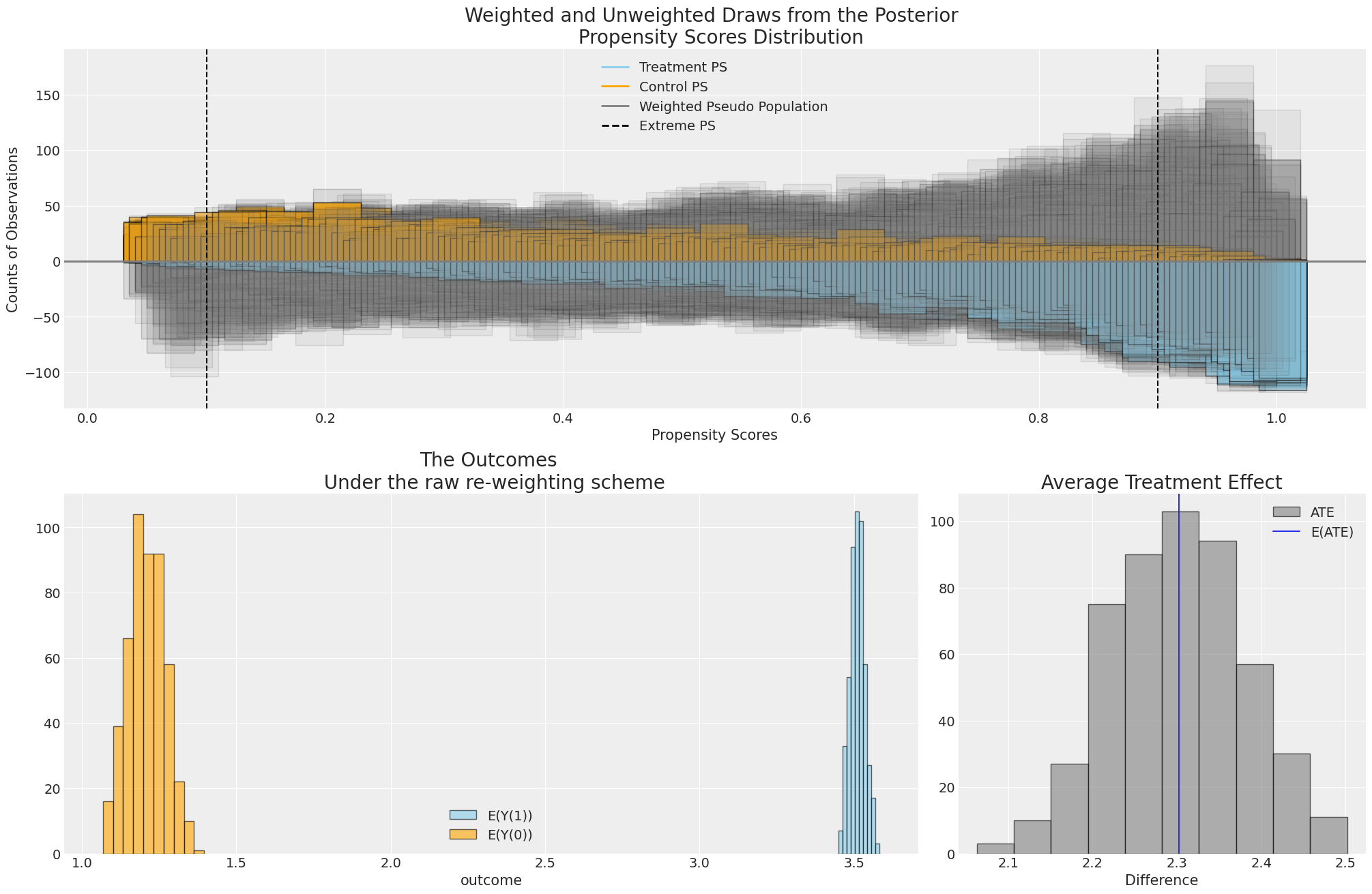
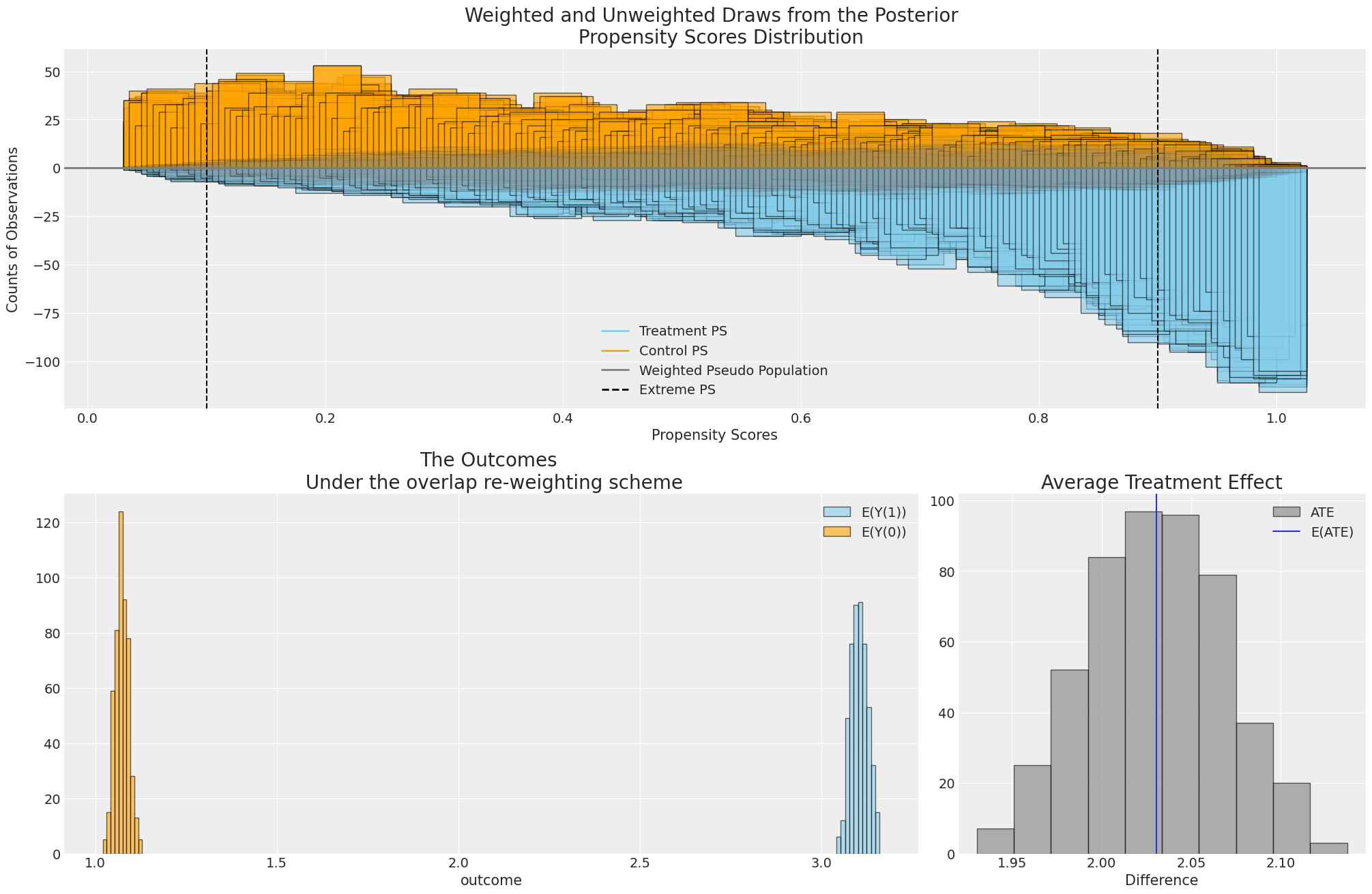
Propensity Weighting Adjusts Outcome Distribution to improve estimation of treatment effects
Conclusion
- Uncertainty in the Model
- Causal inference wrestles with the uncertain consequence(s) of assumed data generating processes.
- Bayesian Causal Inference takes uncertainty quantification seriously
- Prior sensitivity Analysis further establishes the robustness of our estimates under uncertainty
- Uncertainty about the Model
- The combinatorial complexity of the possible models necessitates informed opinion to zero-in on plausible models
CausalPy streamlines the deployment and analysis of these causal inference models with proper tools to asses their uncertainty, and communicate impact of policy changes.
Faciliates model evaluation, comparison and combination - to build credible patterns of inference and justified approaches to critical decisions.