| JW1 | JW2 | JW3 | UF1 | UF2 | FOR | DA1 | DA2 | DA3 | EBA | ST | MI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.046719 | -1.472334 | -1.649844 | -0.740886 | -0.573890 | -0.992347 | 1.269461 | 1.805128 | 1.230402 | -0.039732 | 1.618562 | -0.169659 |
| 1 | -1.649857 | -1.908889 | -1.841327 | 0.120929 | -0.939917 | 0.401440 | 0.177058 | 0.126041 | -0.004604 | -0.806541 | 0.930899 | -0.438887 |
| 2 | 0.429099 | 1.826533 | 0.341107 | 1.033988 | 1.287623 | 0.490457 | -0.627370 | -0.717461 | -0.246633 | 0.261212 | 0.913639 | 0.496846 |
| 3 | 0.257582 | -0.315831 | 1.258474 | 0.241065 | -0.548987 | -0.247273 | 0.858847 | 0.964730 | 1.233870 | -0.251100 | 0.466743 | 0.169622 |
| 4 | -0.875969 | -0.263046 | -0.947966 | -0.231731 | -0.850588 | 0.860900 | 0.989963 | 0.671778 | 0.438236 | -0.129382 | 2.266723 | -0.951899 |
Bayesian Workflow with SEMs
PyCon Ireland 2025
2025-11-16
Preliminaries
Who am I?
- I’m a data scientist at Personio
- Bayesian statistician,
- Reformed philosopher and logician.
- Website: https://nathanielf.github.io/
Code or it didn’t Happen
The worked examples used here can be found here

My Website
Craft in Statistical Modelling
- Embraces process, imperfection, and iteration.
- Aims at the acquisition of scientific knowledge
- Supports generalisable findings and solutions
- Restore ownership: you shape, test, and refine — the model carries your imprint.

Checklists in Statistical Modelling
- Reduce inquiry to compliance: ticking boxes replaces genuine understanding.
- Create the illusion of rigor while bypassing uncertainty and context.
- Confuse progress with throughput: more boxes checked ≠ better science.
- Promotes shallow levels of engagement, infantalises the management class. Hinders effective decision making.
- Strips away ownership: you don’t make something, you just complete a task.
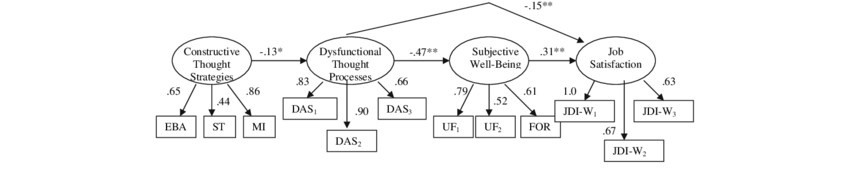
Job Satisfaction Data
- Constructive Thought Strategies (CTS): Thought patterns that are positive or helpful, such as:
- Self-Talk (positive internal dialogue):
ST - Mental Imagery (visualizing successful performance or outcomes):
MI - Evaluating Beliefs & Assumptions (i.e. critically assessing one’s internal assumption:
EBA
- Self-Talk (positive internal dialogue):
- Dysfunctional Thought Processes: (
DA1–DA3) - Subjective Well Being: (
UF1,UF2,FOR) - Job Satisfaction: (
JW1–JW3)
Contemporary Bayesian Workflow
- Start with Theory and Prior Knowledge
- Iterate with Checks and Visual Diagnostics
- Refine Structure and Layer Complexity
- Assess consistency of Signal
- Validate through Sensitivty Analysis
- Own the Process



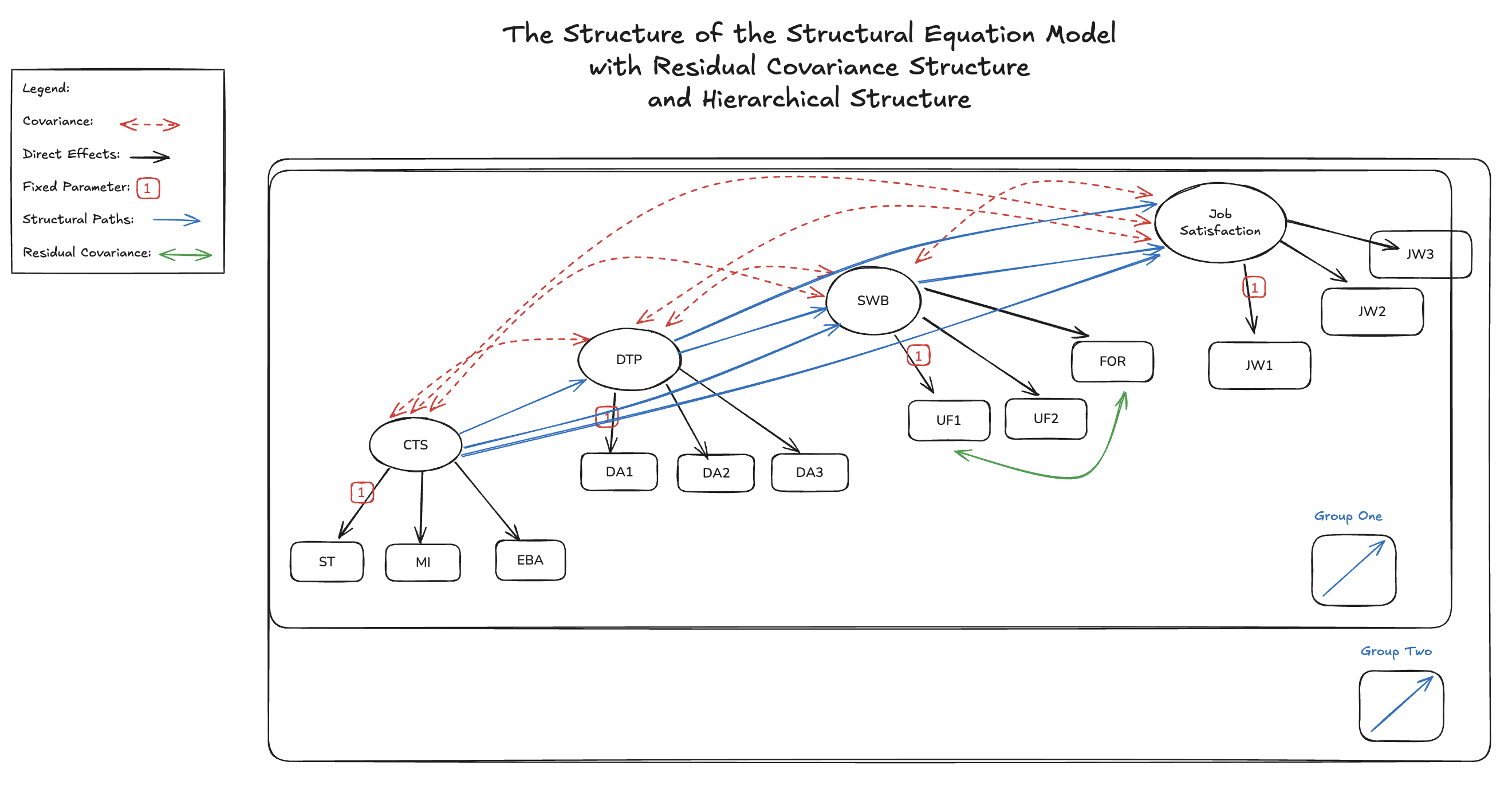
The Confirmatory Factor Structure
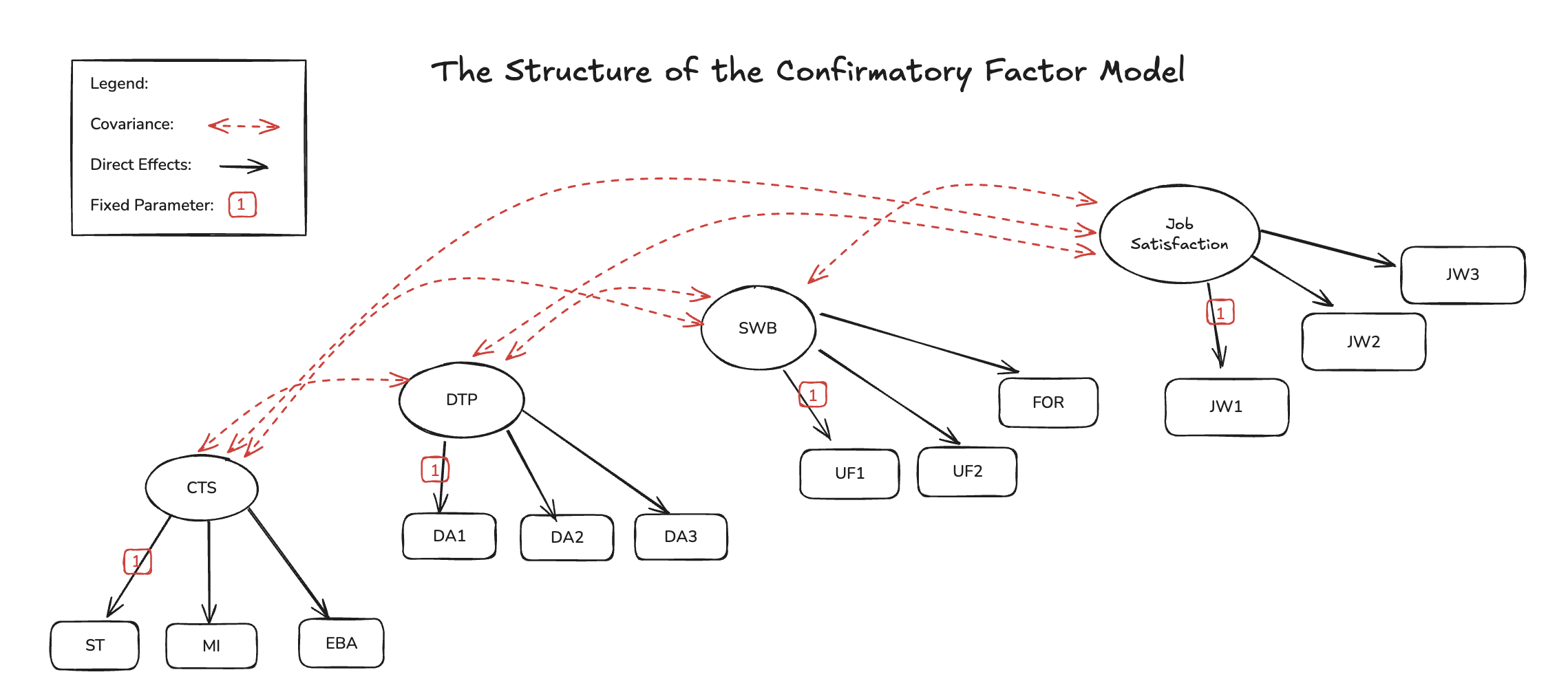
Bayesian Workflow with SEMs
CFA Implications
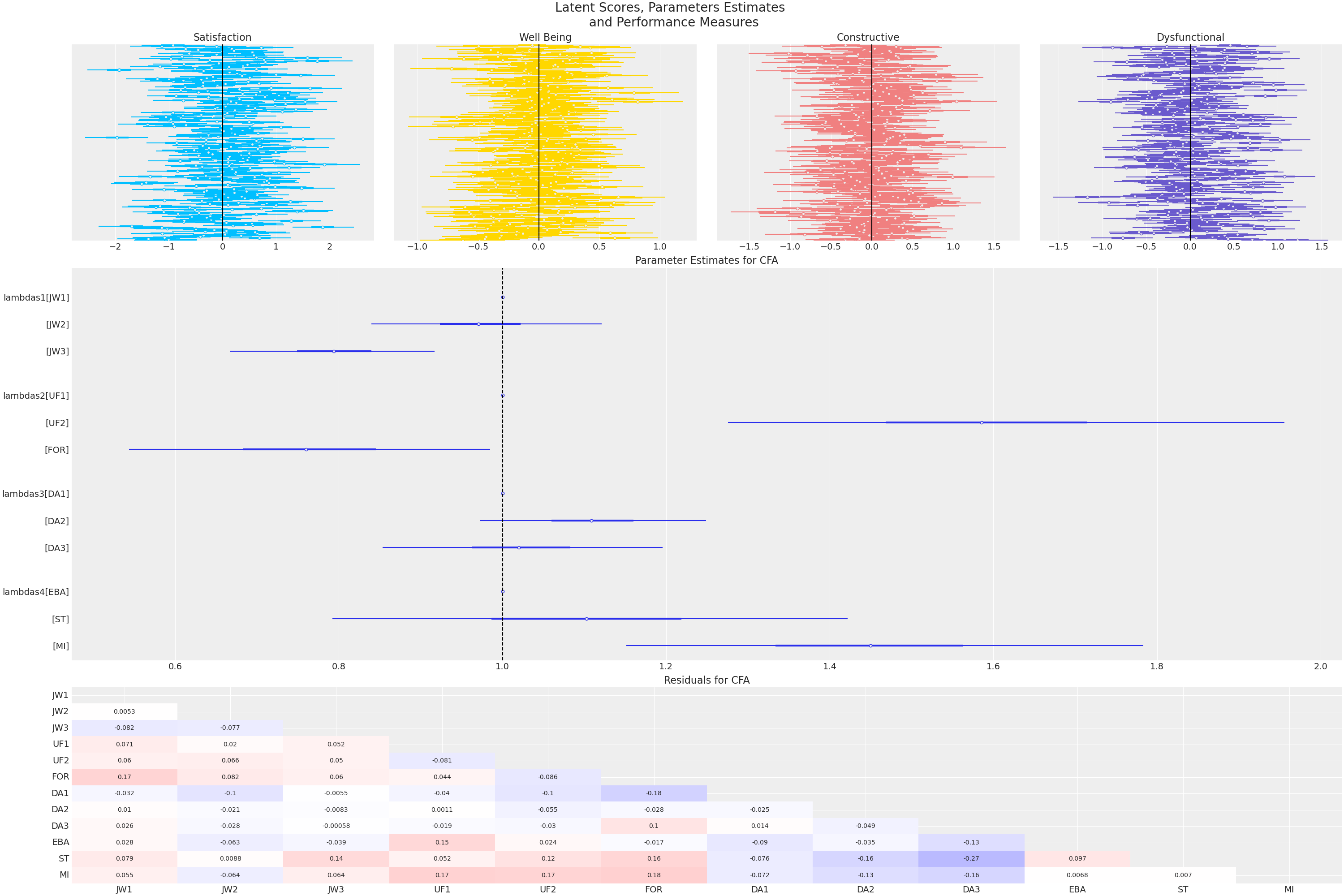
- Estimated Factor Loadings are close to 1
- The indicator(s) are strongly reflective of the latent factor.
- Posterior Predictive Residuals are close to 0
- Latent factors move together in intuitive ways.
- High Satisfaction ~~ High Well Being
The SEM Regression
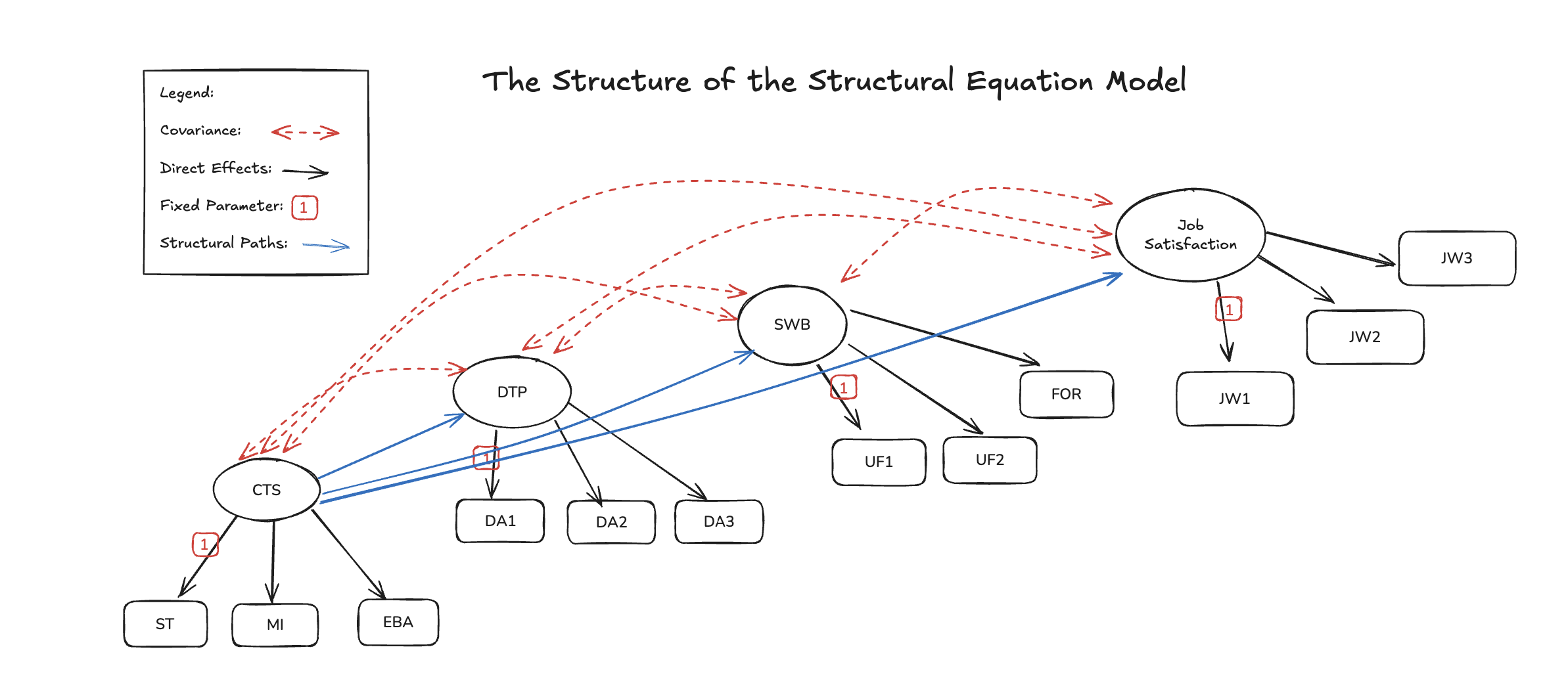
The SEM Regression
with Mediation Effects
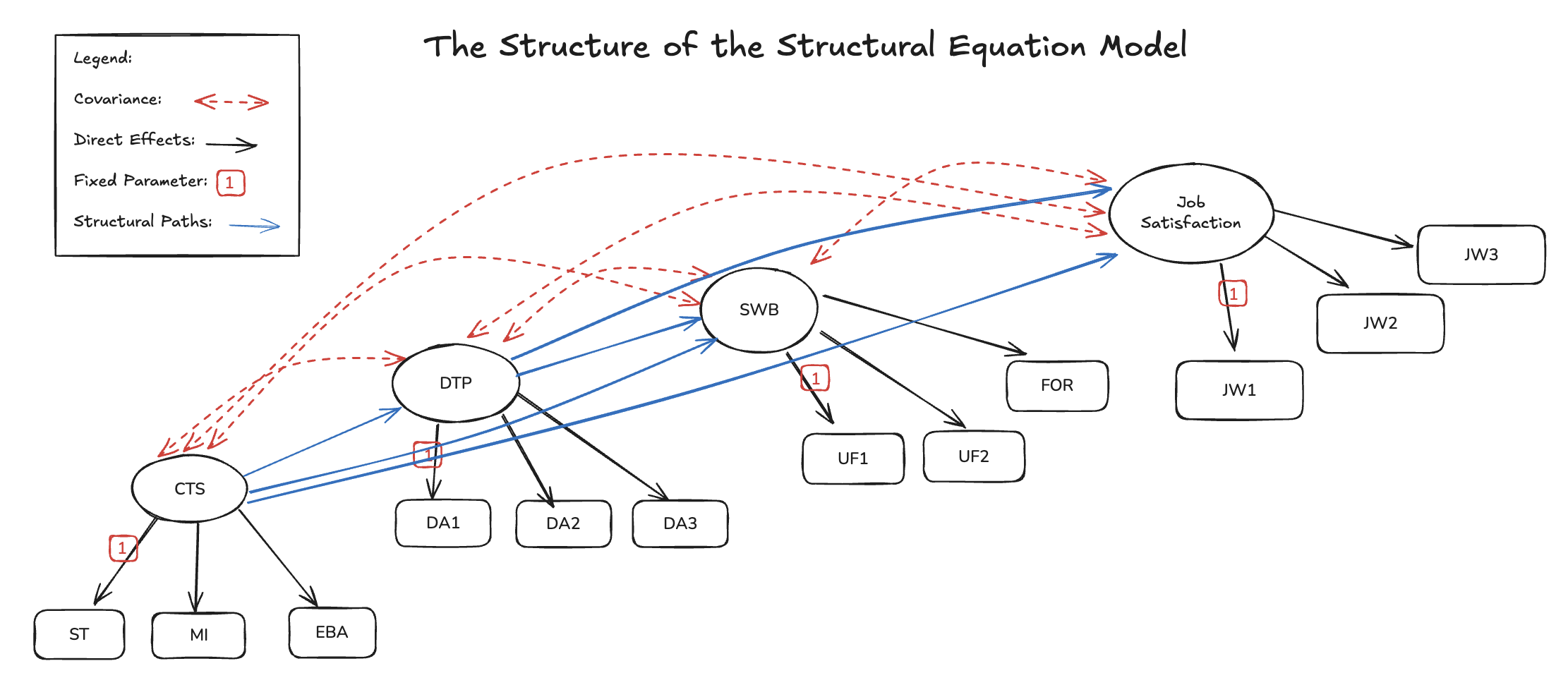
The SEM Regression
with Staggered Mediation Effects
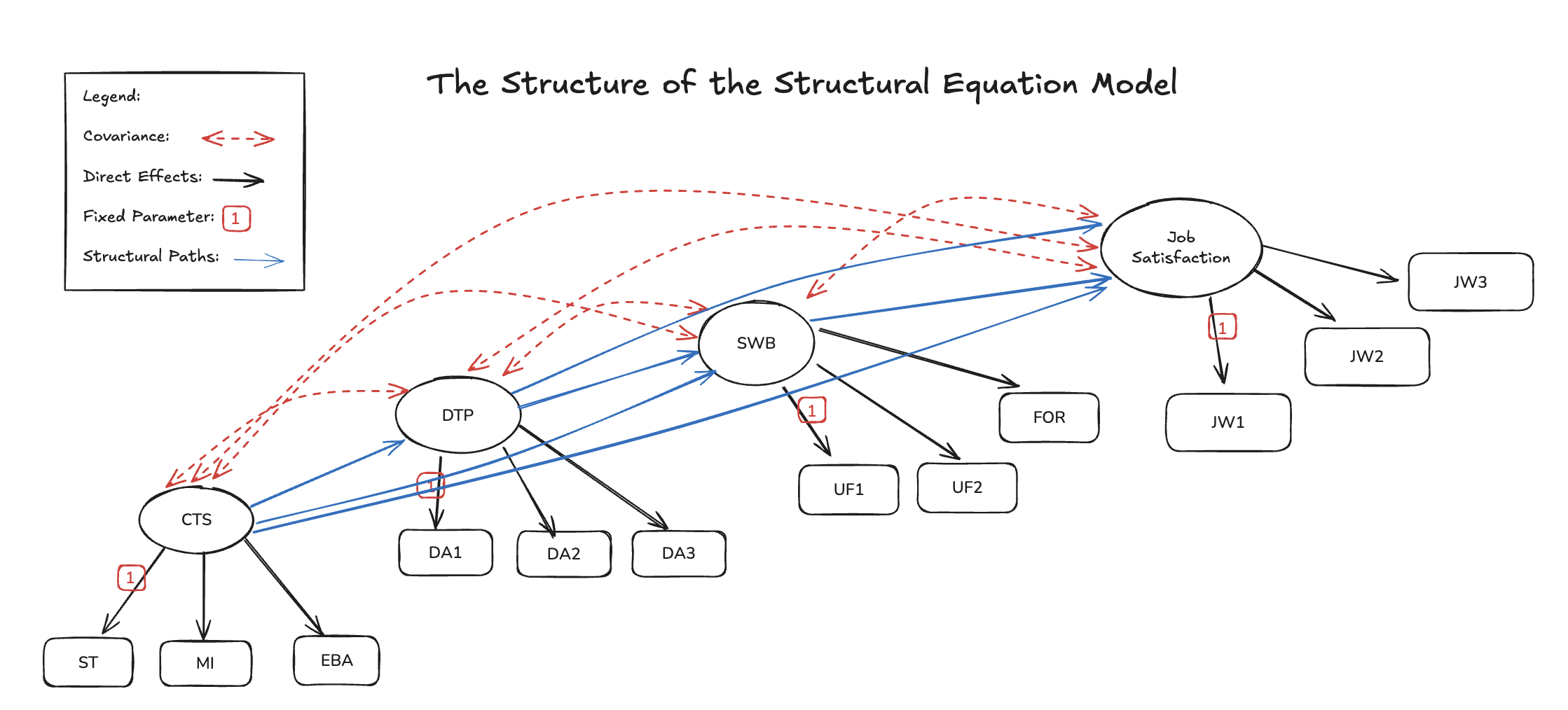
The SEM Regression
with Residuals Covariance Structures
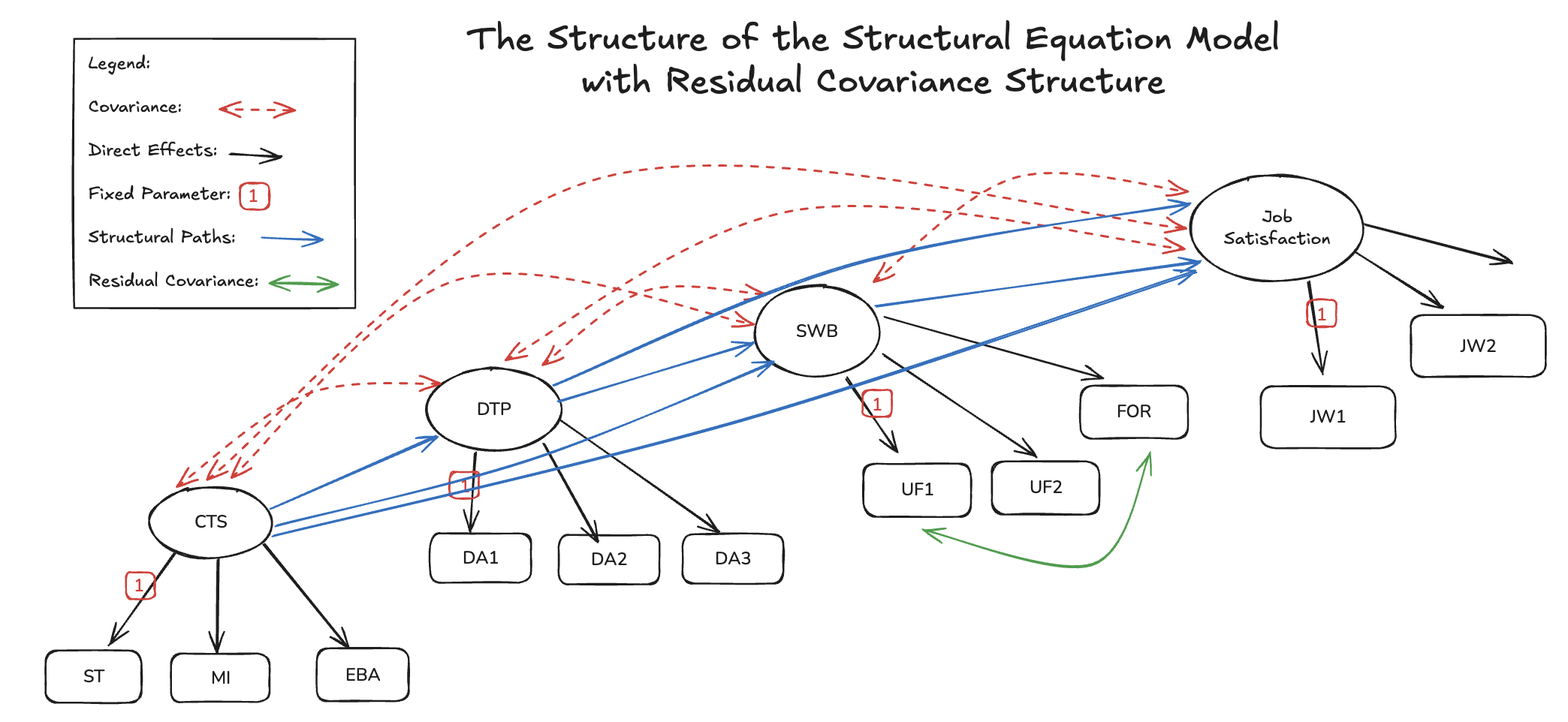
Bayesian Workflow with SEMs
SEM Implications

- The Beta coefficients encode the directional effects of the latent constructs on one another
- High Dysfunction -> Negative Impact on Satisfaction
- Factor loadings remain close to 1
- Posterior Predictive of the Residuals have Improved
Bayesian Workflow with SEMs
Mean Structure Implications

- Mean Structure Parameters \(\tau\) show poor identification
- Beta coefficients and Factor Loading Estimates consistent with prior models
- Posterior Predictive check on Residuals provide evidence of a good fit.
Bayesian Workflow with SEMs
Comparing Model Estimates
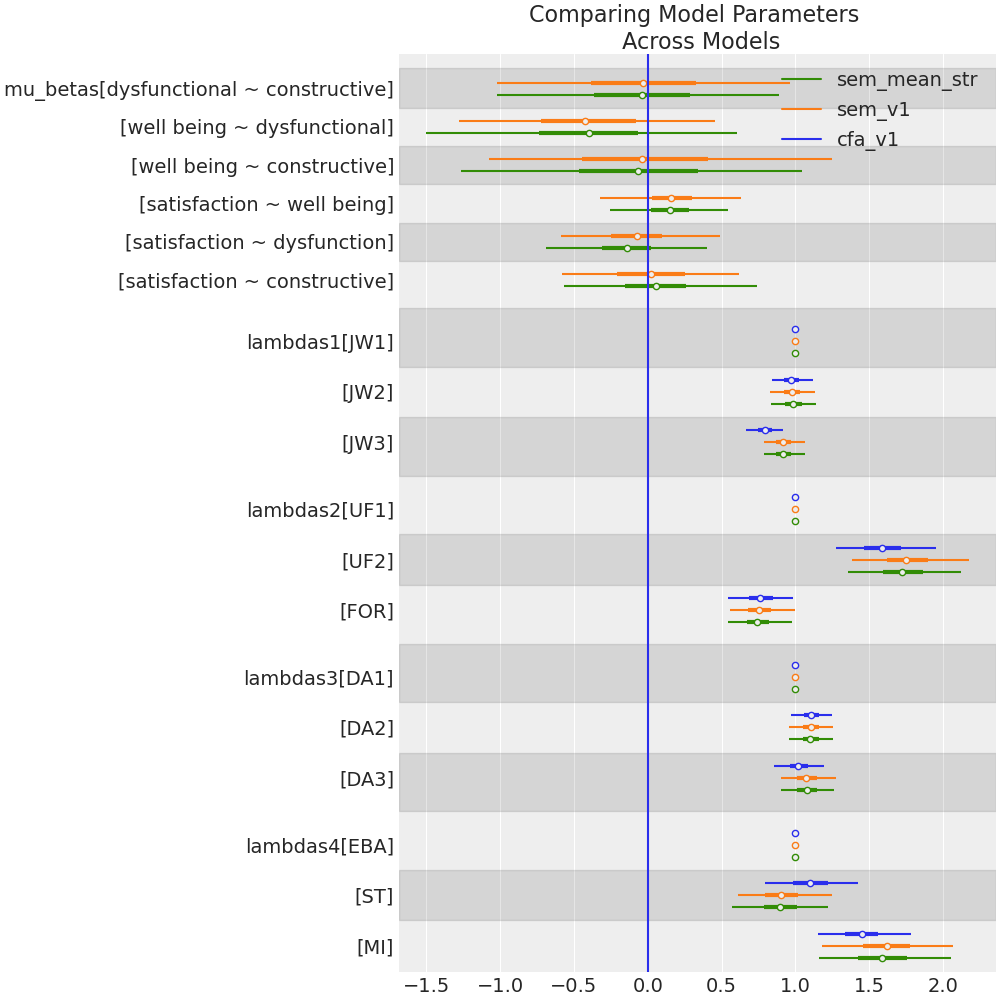
- The measurement model is stable: adding the structural paths did not disrupt how the latent variables are measured.
- SEM is not introducing distortions into the factor structure.
- The hypothesized regression paths are consistent with the observed covariance patterns.
- Constructive thought processes: self-talk, visualisation and evaluation of beliefs improve job satisfaction.
- Effects are achieved directly and indirectly through overall well being.
Bayesian Workflow with SEMs
Assessing the Indirect Effects

Variations on theme
with Hierarchical Structure
Parameter Recovery
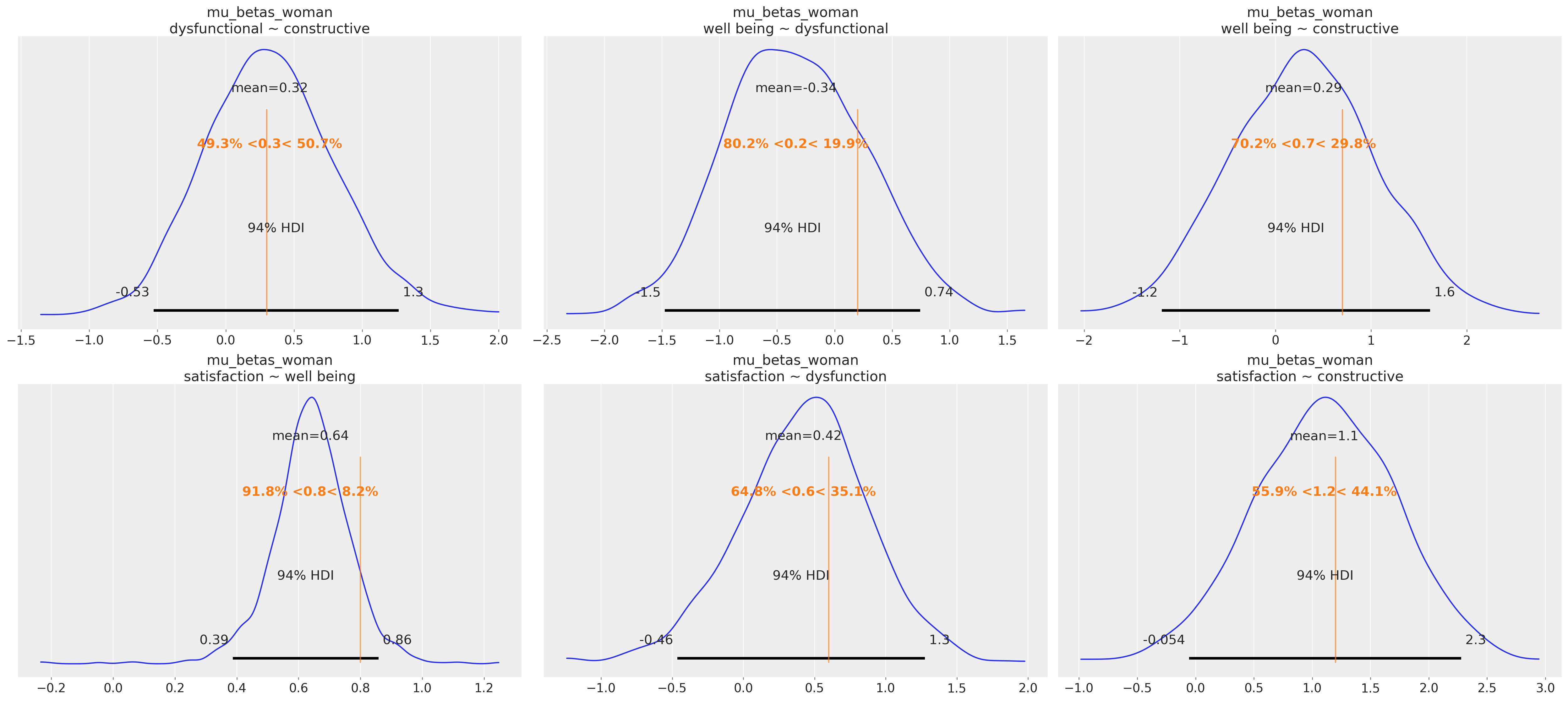
Complex models require proper validation methods. Parameter recovery methods are the best way to test the model’s ability to identify the correct effects.
Craft as Discovery
“Abandon the idea of predetermination, the shaping force of your intentions…rely less on the priority of your intentions and more on the immediacy of writing… You’ll see that some of your sentences are still conjectural… start noticing the thoughts and implications surrounding them.” - Verlyn Klinkenborg in Several Short Sentences about Writing”
- Modeling, like writing, is an act of exploration.
- Expect surprises and anomalies—they teach more than preconceptions.
- Embrace uncertainty; allow the data to guide the process.

Craft as Discipline
” [T]he goal is to represent the systematic relationships between the variables and between the variables and the parameters … Discrepancies between the model and data can be used to learn about the ways in which the model is inadequate for the scientific purposes at hand, and thus to motivate expansions and changes to the model … a model is a story of how the data could have been generated; the fitted model should therefore be able to generate synthetic data that look like the real data; failures to do so in important ways indicate faults in the model.” - Gelman & Shalizi in Philosophy and the practice of Bayesian statistics

- Building statistical models is inherently iterative and expansionary
- Assumptions are encoded transparently and their implications are assessed for cogency
- Where our assumptions fail, they are revised or rejected. Building confidence and clarity.
- The process yields compelling, justifiable conclusions worthy of your work.
Conclusion: Workflow as Craft
“Here, in short, is what i want to tell you. Know what each sentence says, What it doesn’t say, And what it implies. Of these, the hardest is know what each sentence actually says” - V. Klinkenborg

- In modelling, as in writing, clarity emerges through revision.
- The Bayesian workflow with PyMC teaches us to listen to our models — to read them aloud through simulation, recovery, and critique.
- Each iteration reveals what the model truly says, what it hides, and what it implies.
- Craft lies in that attention — in resisting flattening automation, and choosing understanding over throughput.
- Through this care, our models become not only more compelling, but more robust — resilient to noise, misfit, and misuse.
