Missing Data and Bayesian Imputation with PyMC
Causal Narratives in Survey Analysis
4/25/24
The Data
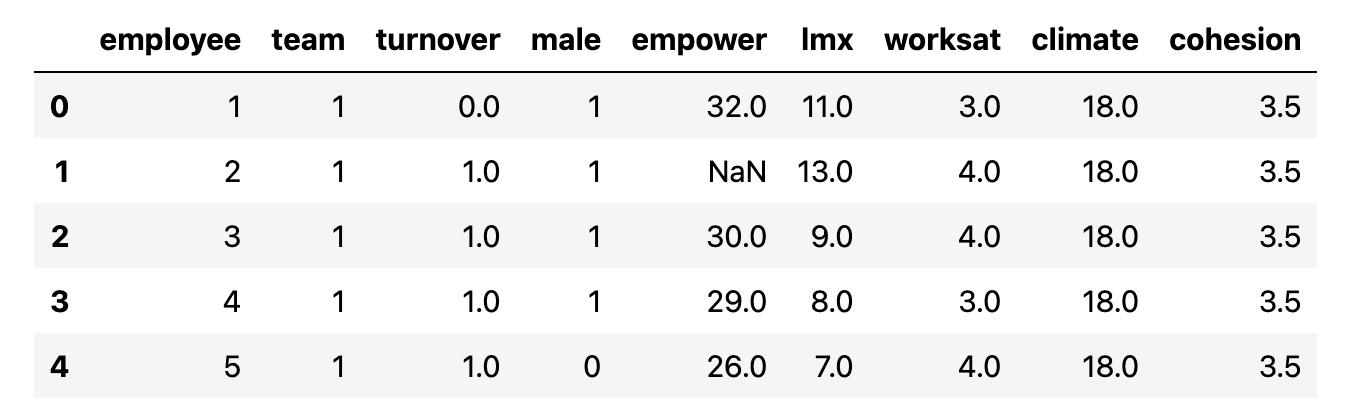
Employee Empowerment Survey
The Metrics

Metrics with Gaps
Estimated Model and Samples
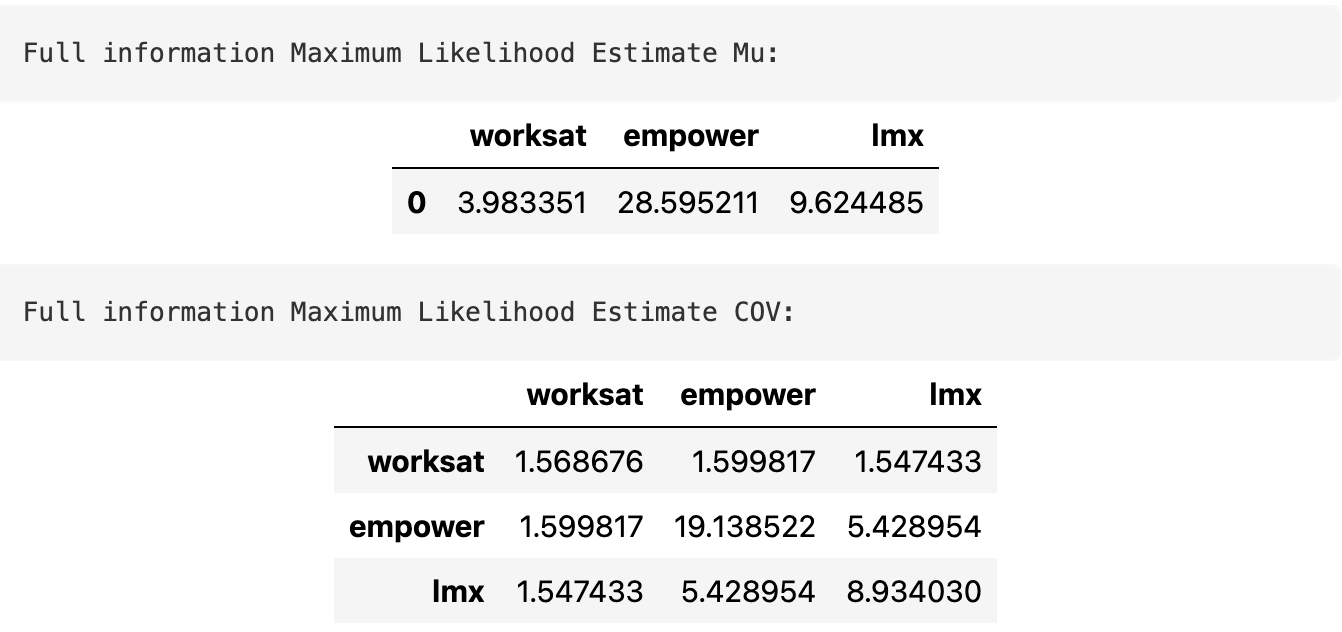
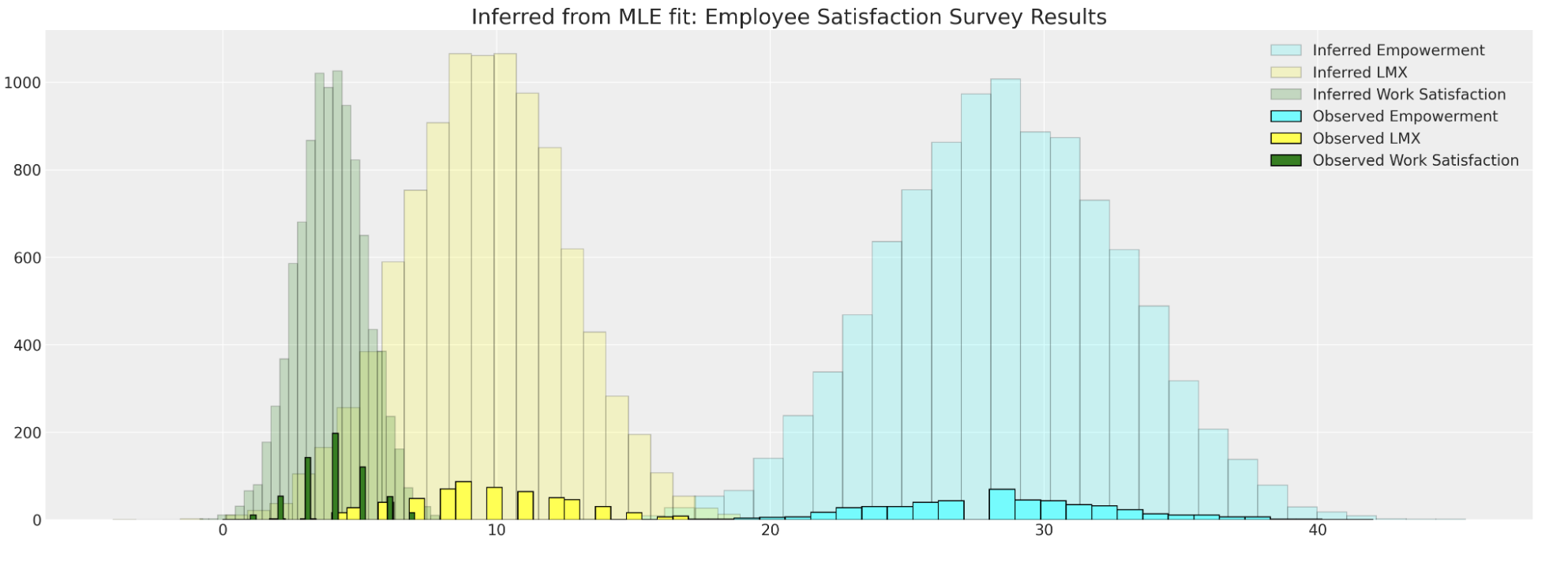
The Estimated model Parameters are used to sample from the implied distribution.
But the approach lacks control and insight into why the data was missing in the first place.
Cannot directly account for MNAR cases.
Probabilistic Maps
Sampling the possible spaces over missing data

The idea
- When gaps in survey data are not random
- We need to understand the drivers of missing-ness
- The “topology” around the gaps gives us clues
- Bayesian inference helps to imputes the probable inclines and curves of the space in the gaps conditional on the observed data.
- In our employee engagement data the question becomes - What are the enviromental influences on the probable responses?
The Model Structure
The PyMC model Graph
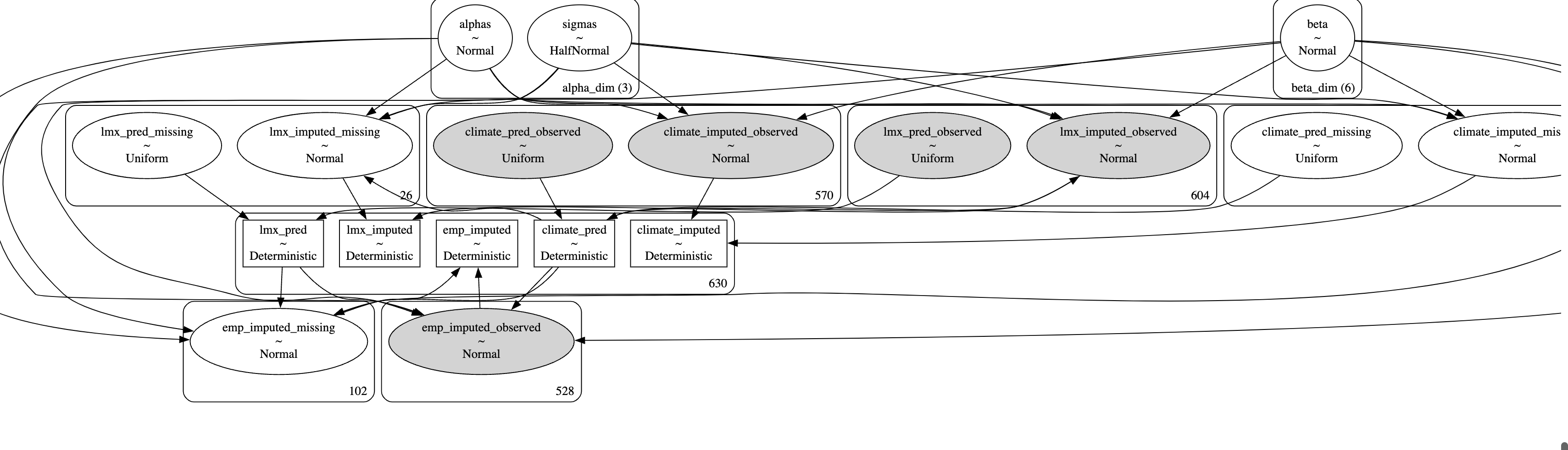
Chained Equation Model
Imputing the values and feeding them forward into the ultimate likelihood terms to estimate the profile of the joint distribution.
Sensitivty to Prior Specification
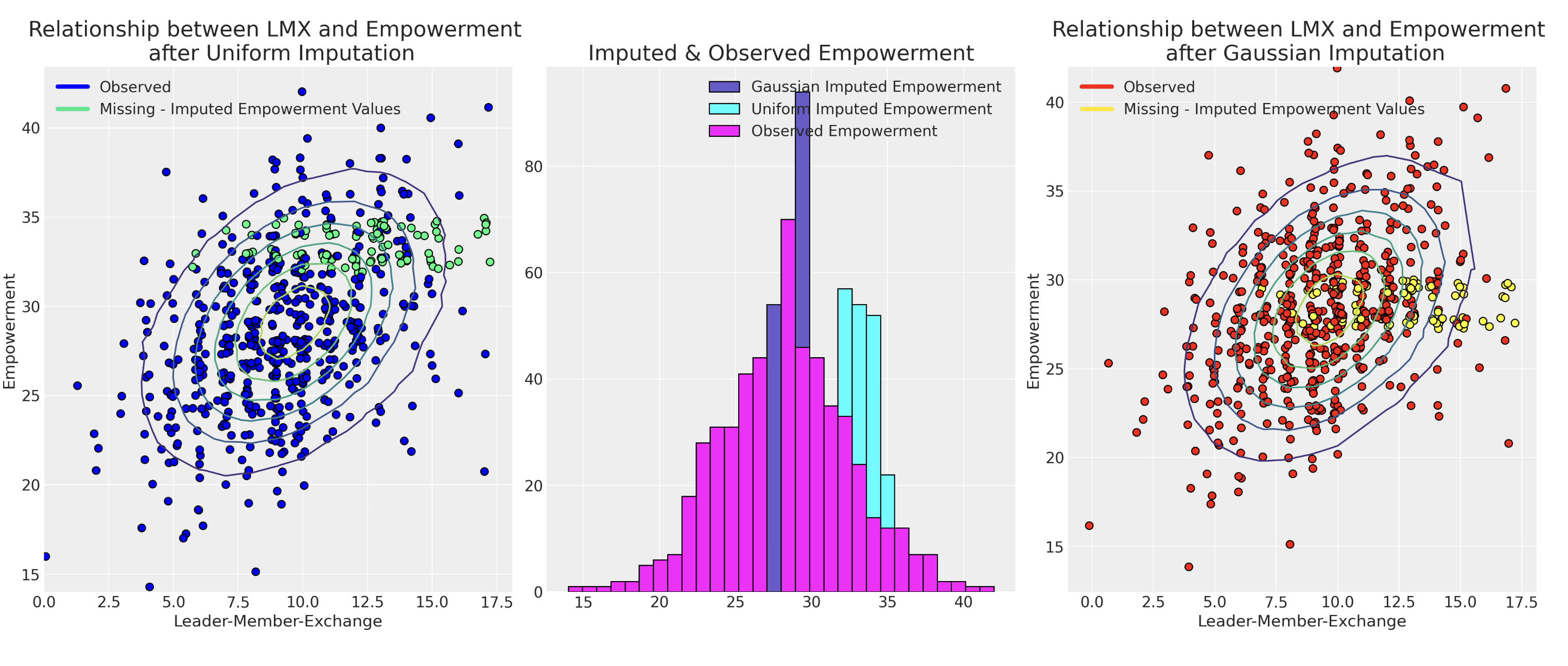
The Effect of choosing the right Priors
Model choice using predictive adequacy as a constraint. Bayesian model adequacy workflow applies here too
Hierarchical Structures of Non-response
Team dynamics determine probability of response

Team Empowerment Scores
We can try to recover ignorable missing-ness i.e moving to MAR from MNAR conditional on group specific random effects.
Hierarchies and Human Relations
Power Structures Interactions
![]()

Model Structure
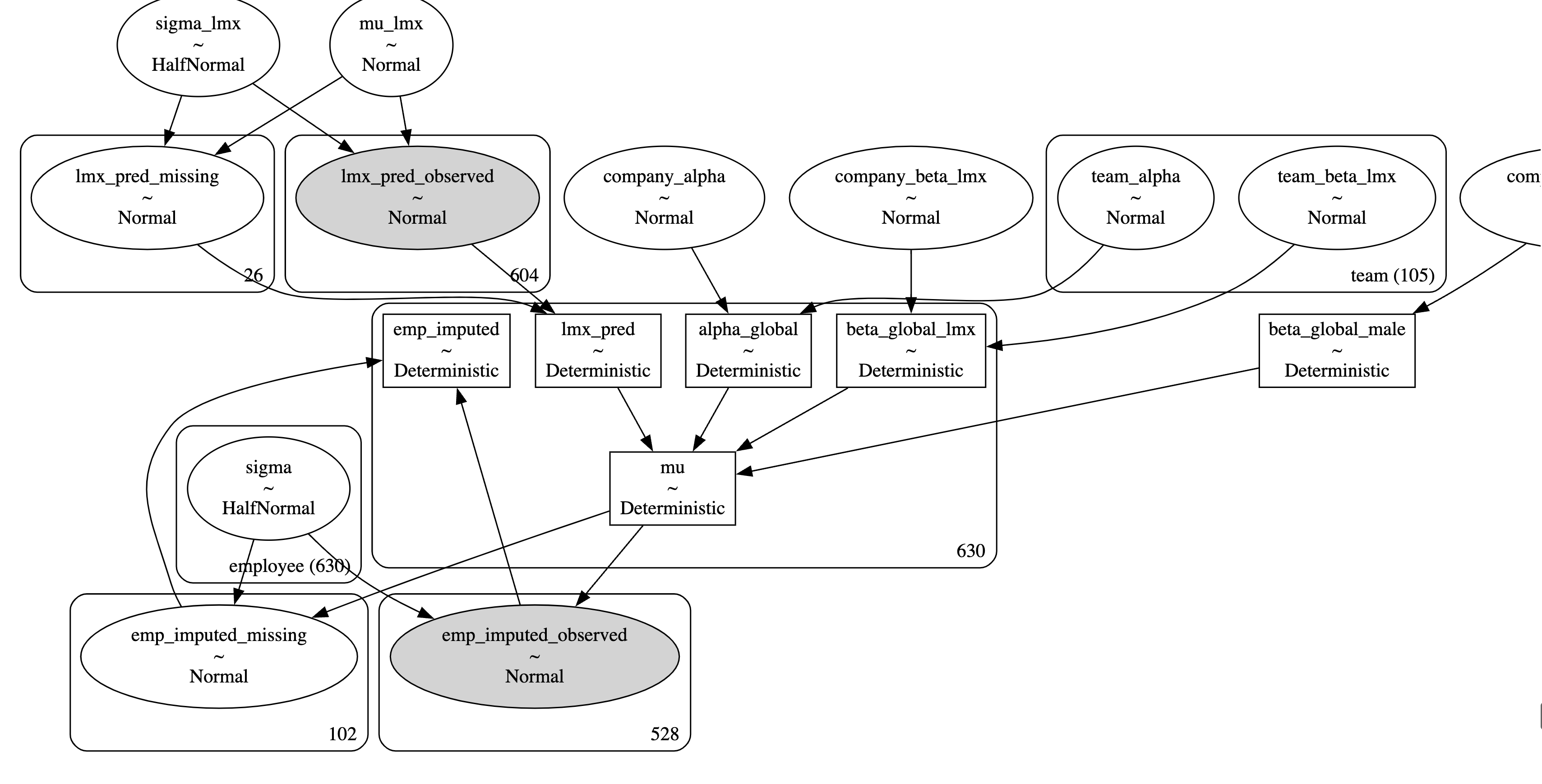
Hierarchical Team based Model
Influence of Team Membership
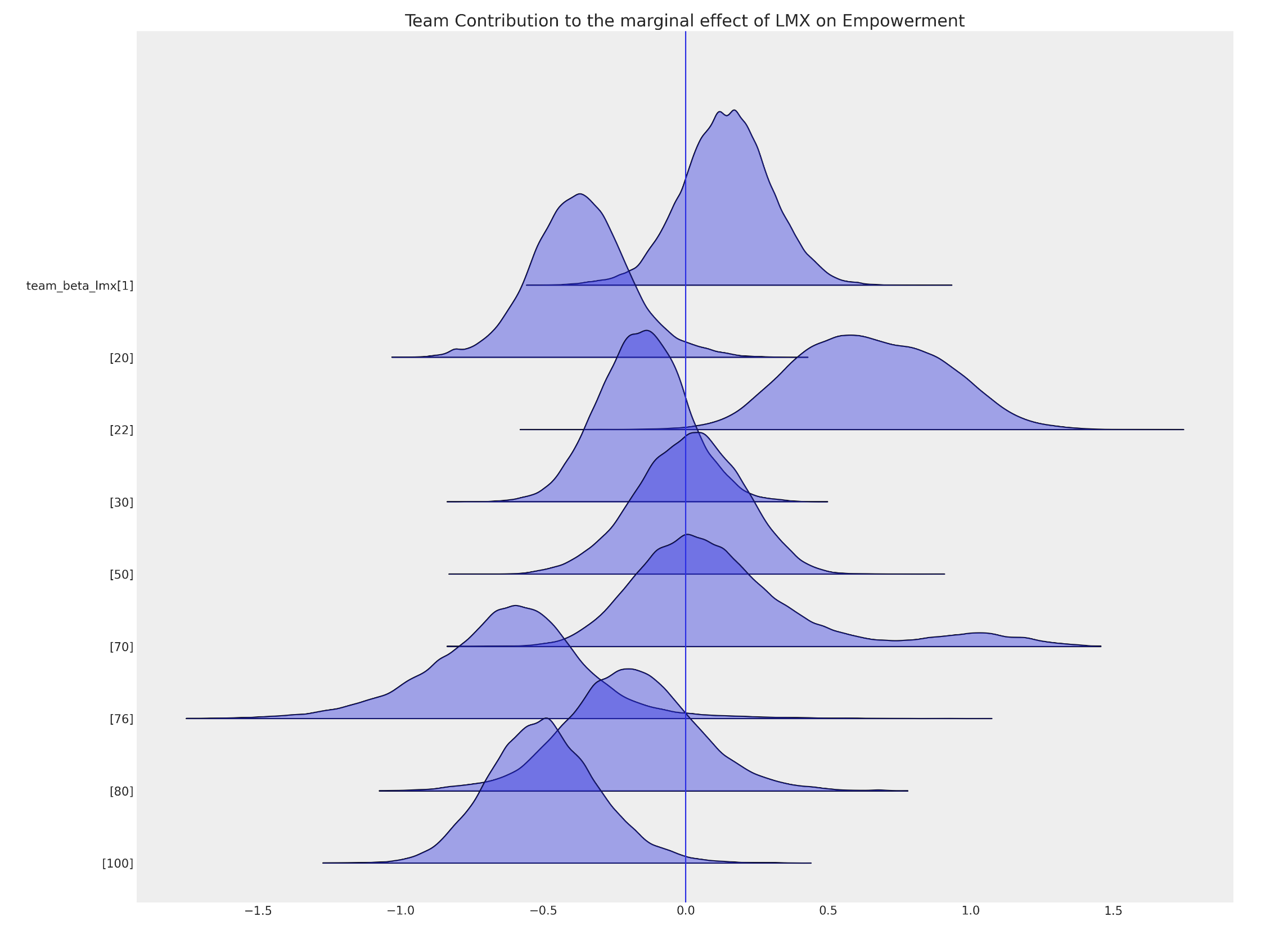
Modification of Leader Impact based on Team imputed with Uncertainty
Imputation with Team Effects
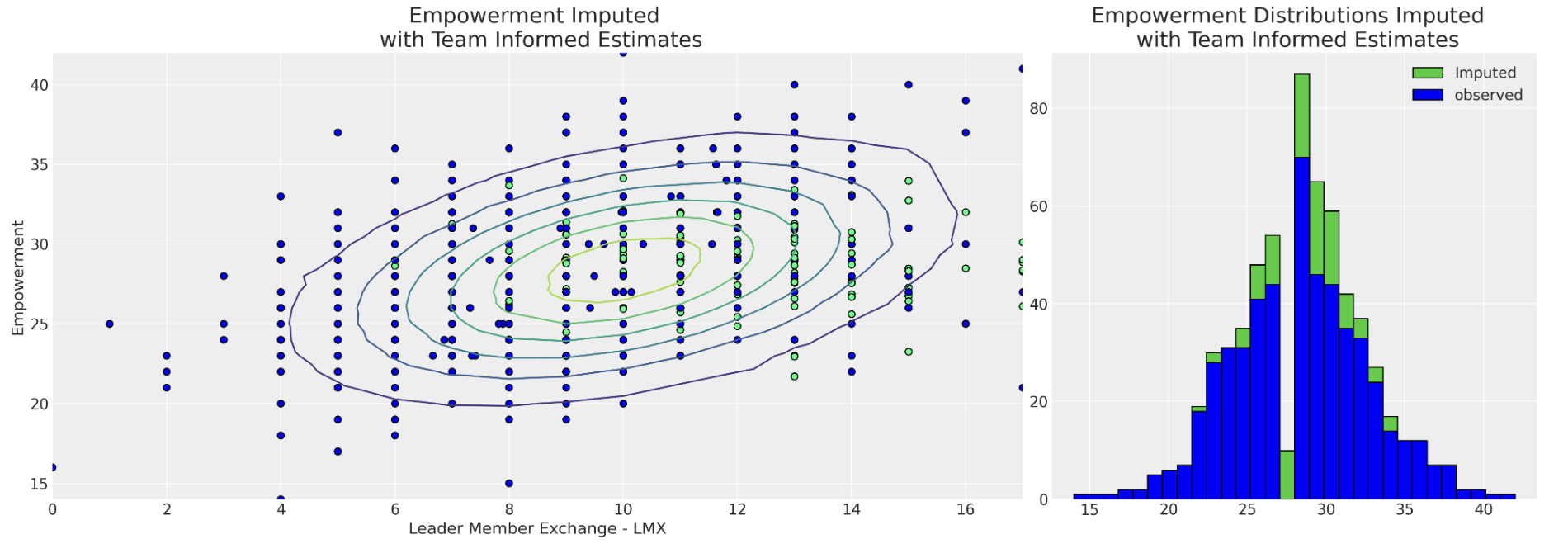
Imputation patterns under team influence
Recap and Conclusion
We’ve seen the application of missing data analysis to survey data in the context of People Analytics.
Multivariate approaches are effective but cannot help address confounding bias,
The flexibility of the Bayesian approach can be tailored to the appropriate complexity of our theory about why our data is missing.
Hierarchical structures pervade business - conduits for leadership influence/communication channels. Hierarchical modelling can isolate estimates of this impact and control for biases of naive aggregates.
- Reveal inefficiencies and mismatches between team and management.
Imputation gives “voice” to the missing. Inverse Propensity weighting corrects mis-representative samples. Both are correctives for selection effect bias.
